
Writing Errors: The Case of English Learners of Arabic
Asmaa Shehata (Oxford (MS), USA) & Amaya Martin (Arlington (VA), USA)
Abstract
Errors made by second language (L2) learners are problematic and frustrating to both learners and teachers. This study aimed to find areas of difficulty in writing among learners of Arabic. It examined the types of errors that learners of Arabic who were first language (L1) English speakers made in writing and investigated the influence of language proficiency on learners’ writing errors. To this end, 30 essays were collected from learners of Arabic at three different class levels: beginner, intermediate and advanced. The findings indicated that learners made more grammatical than lexical and spelling errors. While definiteness was the most frequent error made by first- and second-year learners, noun-adjective agreement was the most common type of grammatical error made by third-year learners. The results hold implications for the type of input introduced to L2 learners to improve their language learning.
Keywords: Error analysis, Arabic, writing, language class levels
1 Introduction
Writing is a productive skill that represents a crucial competence for L2 learners to express and convey ideas to readers and acquire other productive and receptive skills as well. To develop learners’ language skills, improvement in writing is required. Prior research has asserted the significant role that writing plays in second language acquisition (SLA). For example, Bjork & Raisanen (1997: 8) argued that writing is “a tool for language development, for critical thinking and extension, for learning in all disciplines”.
Despite its significance, however, previous research has indicated the difficulty of writing, which is seen as a complicated cognitive task for language learners who tend to make writing errors that impede communication and, in turn, fail to deliver the target message properly to readers (Amiri & Puteh 2017). Having studied learners' writing errors in depth, previous research has identified several reasons that contribute to the difficulty of L2 writing, such as lack of grammatical knowledge, first language interference, learners' attitudes towards writing, lack of practice opportunities and teachers' attitudes and teaching methods (Zafar 2016). Despite its importance, very few studies have explored the errors in writing made by learners of less commonly taught languages such as Arabic, which is the focus of this paper. The present study aims to expand the research available in this area by investigating the common errors made by adult learners of Arabic and examining errors in relation to samples from different class levels.
2 Literature Review
Errors in writing are viewed as an integral part of the writing process that should be well studied because they “provide to the researcher evidence of how language is learned or acquired, what strategies or procedures the learner is employing in the discovery of the language” (Corder 1967: 167). Gass & Selinker (2001), however, indicate that learners’ errors provide evidence of their knowledge of the target language and enable teachers to help students improve their ability to self-correct. Unlike mistakes that learners make due to fatigue or lack of attention that can be corrected when asked, an error is defined as “a systematic deviation made by the learner who has not yet mastered the rules of the target language” (Rustipa 2011:18).
2.1. Theoretical Approaches to Writing Errors
To help learners overcome the difficulty of writing; therefore, researchers have used different approaches to study them such as Contrastive Analysis (CA) and Error Analysis (EA). Rooted in structural and behavioural theories which were dominant in the 1940s and 1950s, CA claims that language learners “tend to transfer the forms and meanings, and the distribution of forms and meanings of their native language and culture, to the foreign language and culture” (Lado 1957: 2). In other words, L2 learners transfer the rules of their first language to the target language. The greater the differences between the two languages, the more difficult it is for learners to experience learning the target language. When the two languages are similar, positive transfer takes place and the learning process is facilitated (Qaid & Ramamoorthy 2011). When the two languages are highly different, however, negative transfer occurs and causes errors (e.g. Alasfour 2018). Several scholars have criticised CA because of its emphasis that a learner’s mother tongue is the reason behind that learner’s errors. For example, Whitman & Jackson (1972: 40) state that CA “is inadequate, theoretically and practically, to predict the interference problems of a language learner”.
In response to the contrastive analysis theory, Error Analysis (EA) emerged and was developed by Pit Corder in the 1970s and described as “a research tool characterised by a set of procedures for identifying, describing, and explaining L2 learners’ errors” (VanPatten & Benati 2010: 28). EA is associated with the interlanguage theory (1) that refers to learners’ knowledge of the target language to be a unique and different system for learners’ first and second languages. It aims to explore L2 learners’ errors by comparing their norms with their counterparts in the target language and explaining them (Sawalmeh 2013). Despite the criticism directed to the EA approach due to its focus on learners’ negative performance and inattention to what they do correctly, it remains to be seen as “a useful procedure for the study of second language acquisition” (Saville-Trroike 2012: 42).
The predictability of errors was the primary area of disagreement between proponents of CA and EA. Researchers found that categorising errors or merely comparing linguistic structures did not accurately predict errors because errors are influenced by a wide range of factors, such as developmental stages, interlanguage processes, and individual learner differences (Larsen-Freeman & Long 1991 Selinker 1972). Researchers then started to relativise both CA and EA, adopting a more eclectic approach that considers information from different theoretical perspectives. Errors were thus recognised not just as an outcome of L1 influence but also as intricate reflections of the learner's evolving interlanguage system. This insight caused the focus to change from attempting to forecast errors to understanding the dynamic and complex nature of language learning (Ellis & Barkhuizen 2005).
2.2.Writing Errors in Second Language Acquisition
Numerous studies have examined the writing errors made by learners of English from different L1 backgrounds. For instance, Mariko (2007) explored the common grammatical errors made by 422 Japanese learners of English who were at different language proficiency levels. The researcher analysed 30,000 compositions extracted from a corpus of compositions and found that lower-level learners tended to make verb-related errors, unlike advanced learners, who tended to make noun-related errors. The results indicated that noun-related errors are the most difficult to overcome. In addition, Xiaoli (2015) analysed 134 compositions by Chinese learners, discovering that the four main types of lexical errors made by learners included redundancy, absence, substitution, and part of speech. L1 interference and partial knowledge of the English language were identified as the main sources of learners’ writing errors. Furthermore, Gedion, Tati & Peter (2016) examined the common syntactic errors made by Malaysian learners of English in written compositions. They found that learners’ L1 interference and lack of vocabulary and grammatical knowledge were behind their errors in relation to three categories: verb sentence fragments and punctuation.
In the context of English as a Foreign Language (EFL), Darus & Subramaniam (2009) evaluated essays written by 72 Malay learners of English. Their findings displayed six main types of errors including verb tense, word choice, singular/plural form, prepositions, word order and subject-verb agreement. Similarly, Uthman & Abdalla (2015) examined the writing errors made by 250 Saudi EFL learners majoring in English. Their results indicated that such learners had difficulties with grammar and made many errors caused by L1 interference including tenses, articles, subject-verb agreement, relative clauses, and word order. Sutrisno (2018), using a content analysis method, explored the most and least common writing errors of 18 first term undergraduate English students in East Jakarta, Indonesia. The results indicated that first semester college English students made word form, word choice, and article errors most commonly. Conversely, the least common errors made by learners included word order and incomplete sentences.
2.3 Differences Between Arabic and English
Arabic is one of the languages most people speak worldwide, with speakers spread across a vast region that includes the Arabian Peninsula, the Fertile Crescent, and the Atlantic Ocean. 422 million people consider it their mother tongue (Shehata 2018: 58), and many millions of Muslims in other countries are familiar with it as it is the official language of Islam and the Holy Qur'an (Mitchell 1962: 10, Shehata 2024: 4).
As languages from different linguistic families, Arabic and English have many variances that go beyond their outwardly apparent variations in script and phonology. Unlike English, for example, which is written in Latin script and read from left to right, Arabic texts are written and read in a cursive style from right to left. Moreover, there is no difference between lower and upper case in Arabic, and the punctuation rules are more lenient. The variances between the two languages also include linguistic nuances, structural variants, and cultural components that affect how each language is said and comprehended (Holes 2004). One notable difference is the morphological complexity of Arabic which is distinguished by its rich system of root-based word formation and extensive use of derivational affixes. Arabic grammar is therefore difficult for English speakers learning Arabic to apply, especially the subject-verb agreement, mood, and voice (Wahba, Taha & England 2013). English, on the other hand, relies more heavily on word order and context to convey meaning, making it comparatively more reliant on syntax and semantics. These divergent approaches to word formation and sentence structure result in distinct language nuances and require learners to grasp unique grammatical concepts.
Furthermore, the grammatical aspects of gender and formality play a substantial role in Arabic, influencing word choice and sentence structure that are not present in English. Arabic also features a rich vocabulary and idiomatic expressions deeply rooted in its history and culture. Conversely, English draws from a diverse range of influences, resulting in a lexicon that incorporates words from various languages, reflecting its historical and global context. Additionally, the Arabic sentence has more linguistic options than the English phrase. These include the VSO, SVO, VOS, and OVS structures. However, the grammatical notions of ‘case’ and ‘topicalization’ limit this structural ‘freedom’.Although it does not lead to misconceptions, Modern Standard Arabic (MSA) does not show the case or marking of the last letter in nouns (Holes 2004: 251). The primary reason for this is that MSA follows a standard word order that is mostly set by a principal organisation: the 'new' content, which is typically undefined, always appears before the 'known' information, even if the definite or known content is the grammatical subject or object.
2.4 Error Analysis in Arabic Writing
While several studies have analysed the writing errors made by learners of English from different L1 backgrounds, very few studies have examined errors made by learners of Arabic. For example, Al-Ani (1972) studied writing errors made by Arabic learners in an advanced Arabic composition course. The findings displayed different error categories including grammatical and orthographic errors that were mainly attributed to L1 interference. Despite the interesting results of the study, Al-Ani did not describe the tasks and concluded with a call for further research. In a similar vein, Rammuny (1976) analysed errors conducted in written Arabic by 115 American students from 22 American universities at three different proficiency levels and explored the sources of errors in an attempt to find solutions. The results indicated four main categories of errors: orthographic / phonological (e.g., vowel length, contrasts involving non-English consonants), lexical (e.g. omission and wrong diction), structural (e.g. number agreement, definiteness, and prepositions) and stylistic (e.g. awkward sentence wording and repetition of pronouns). In addition, three sources of errors were identified including teaching strategies that lacked writing practice, interference of learners’ first language (i.e., English) and colloquial Arabic varieties. More recently, Alkadi (2015) investigated the writing errors made by English learners of Arabic by evaluating 120 writing samples written by 44 students, and by interviewing six teachers. The study also collected 82 questionnaire responses from different educational institutions in the United Kingdom. The results revealed four factors that lead to learners' writing errors: teaching and learning strategies, orthographic difficulties, script confusion and phonological realisation. However, Alkadi used different tasks that might have influenced the results. As Corder (1974: 126) explained, “different types of written material may produce a different distribution of error or a different set of error types”.
The review of relevant literature indicates that the study of errors in writing made by adult learners of Arabic has lagged behind that of learners of other languages, and therefore it is the focus of the present study.
3 The Present Study
Recognising the importance of analysing learners' writing errors, which can contribute to better outcomes, a considerable body of research has focused mainly on exploring errors made by learners of English from different L1 backgrounds (Sutrisno 2018). Even so, little is known about errors in writing made by adult learners of other languages, especially at different class levels. Addressing this gap, the purpose of this study is to investigate the common errors made by adult learners of Arabic and to examine whether learners' class level affects their writing errors. The two main questions that guide this study are:
What types of errors appear in essays written by native English-speaking learners of Arabic?
Do learners’ writing errors differ in light of their class level?
4 Method
4.1 Participants
The data for this study was collected from 30 essays written by learners of Arabic studying at three different universities in the United States. While two universities were private and located on the East Coast, the third university was a large state university located in the South. At the time of writing, all learners were undergraduate students enrolled in the second through seventh semesters of Arabic during that fall semester, and all were L1 speakers of English. Their age ranged from 18 to 25 years old, with a mean age of 22.7 years. Nineteen identified as female, and 11 as male. The courses in which they were enrolled used different series of textbooks for Arabic instruction: Al-Kitaab fii Taʿallum al-ʿArabiyya, published by Georgetown University Press (Brustad, Al-Batal & Tunisi 2011, 2013) and Ahlan wa Sahlan, published by Yale University Press (Alosh & Clark, 2010, 2013). Regardless of the textbook used, all courses had the same proficiency objectives, as described in the ACTFL proficiency guidelines description of language levels. The 30 participants were divided into three distinct groups. The first group included first-year learners who were in their second semester of Arabic; the second group comprised those learners who were in their fourth semester of Arabic; and learners who were in their seventh semester of Arabic formed the third group. Throughout this study, we will refer to these groups as first-year, second-year, and third-year students, even though the third-year students comprised learners who studied more than six semesters, which, in most cases, corresponds to three full academic years. The number of learners in each group was ten.
4.2 Tasks and Procedures
Since the objective of the study was to analyse errors made in writing, we collected one essay per student, amounting to ten essays per group, thus 30 essays in total. The essays, which were given to learners as graded assignments, were produced in an unsupervised environment where learners had access to their course materials. Learners chose the topic of their essays; however, for learners in first-year and second-year groups, the instructors either limited the number of options or narrowed the scope of the topic (Appendices A and B). This was done to force learners to use the vocabulary and material that they had studied in class. For first year learners, narrowing the topic also had the objective of prioritising form over content: since the number of vocabulary words commanded by first-year students was still very limited, the purpose of the writing composition was the production of sentences or phrases, not the expression of a complex idea. Third-year students, on the other hand, were required to choose the topic themselves (Appendix C). The instructors also expected students to do research about the topic before writing about it, and both form and content were relevant. Nevertheless, the grade was primarily based on form for all levels and content only served as a bonus for third-year students. The number of words in the essays, which the assignments specified to be no less than a certain number, varied according to the learner's level: from 200 to 300 words for first- and second-year learners to as many as 1,000 words for third-year learners. Furthermore, the assignments of the first-year students were written by hand, but the assignments of the other two groups were typed with the spelling correction deactivated. Samples of the assignment prompts are provided in the appendix section.
4.3 Data Analysis
The two researchers involved in this study first collected the essays and reviewed them to identify and classify learners’ errors into categories. Subsequently, they compared and discussed their findings until they reached agreement on all errors and categories they had identified. The researchers classified errors into three main categories: grammatical, lexical and spelling. An example of each category is presented in Table 1:
Table 1: Example of Each of the Three Main Error Categories (Trans = Translation)
Grammatical errors and lexical errors were subsequently divided into subcategories. Among the grammatical errors, the sub-categories were word order, verb-subject agreement, noun-adjective agreement, verb tense, negation particles, and definiteness. The verb tense subcategory also included instances of wrong case, in addition to the errors made in the imperfect and perfect tenses. The definiteness subcategory did not include cases of noun-adjective agreement in which the definite article was omitted in the noun or in the adjective. This subcategory mainly included cases of defective construct state and nouns that are definite in Arabic by defect but that do not usually have an article in English, such as general concepts or name of places (I go to university vs. أذهب إلى الجامعة/ aḏhab ʾilà al-jāmiʿa [‘I go to the university’]). Lexical errors comprised the following sub-categories: word choice, dialect substitution, connectors, vague meaning, and prepositions. Examples of all sub-categories are found in Table 2:




Table 2: Examples of Each of The sub-categories of Writing Errors
After all errors were categorised, the total number of errors per category and subcategory was added and their percentage of occurrence in relation to the total number of errors in the text was calculated. The percentages of errors per category were calculated first for every essay. Next, the average percentages of errors per category per group were calculated. The data was then entered into SPSS to explore whether learners’ errors differed in light of their language proficiency.
5 Results
The first goal of the study was to investigate the types of errors that appear in essays written by L1 English learners of Arabic. The descriptive statistics associated with learners’ errors across the three learner groups are shown in Table 3:
Table 3: Frequencies and Percentages of Errors
The Results show that the total number of errors of all three levels in the 30 essays produced by the Arabic learners was 1,988. Of these, 44.3% were grammatical errors, 33.9% were lexical errors, and 21.8% were spelling errors. The percentage of errors made by each group of learners in each of the main categories is presented in Figure 1:
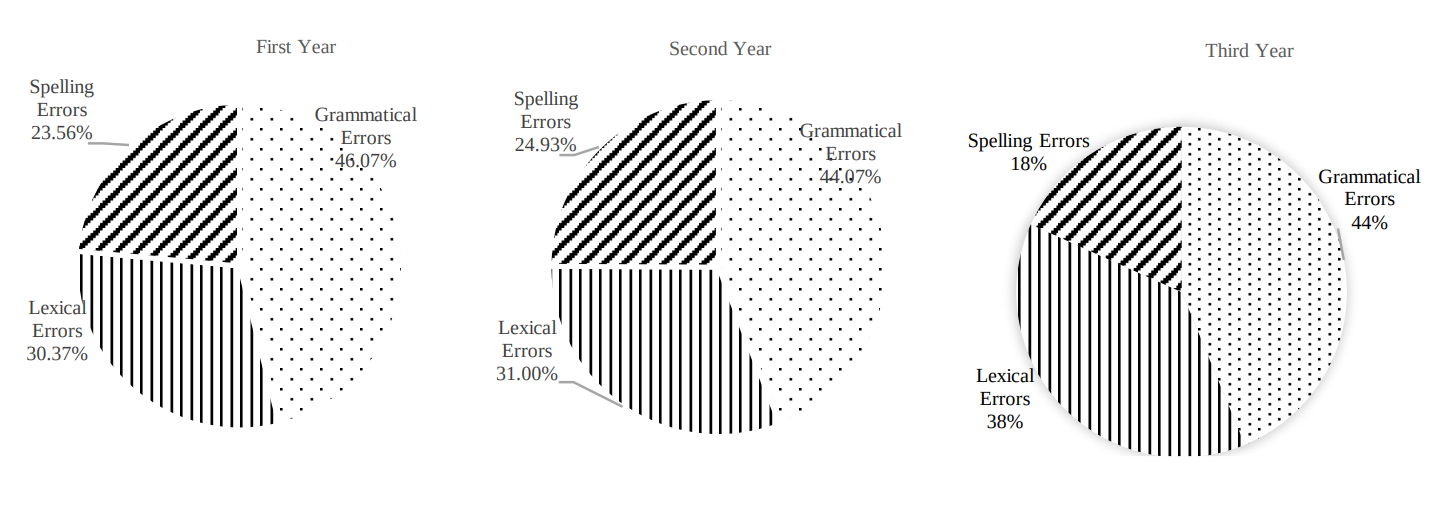
Figure 1: Total Writing Errors by Learners’ Level Of Study
In the grammatical category, third-year Arabic learners recorded the highest percentage of errors (37.8%) followed by second-year Arabic learners (32.9%). However, first year Arabic learners made the smallest number of grammatical errors (17.6%). The same pattern was found in the lexical category in which third year learners made more errors (32.8%) than both second- (23.0%) and first-year learners (11.6%). However, the highest mean of spelling errors was recorded by second-year learners (18.50%) followed by third-year learners (15.4%) and first year learners (9.0%). Within the first two main categories, the percentage of errors in each subcategory differs by level of study. The percentage of errors for the grammatical errors category is shown in Figure 2 below:
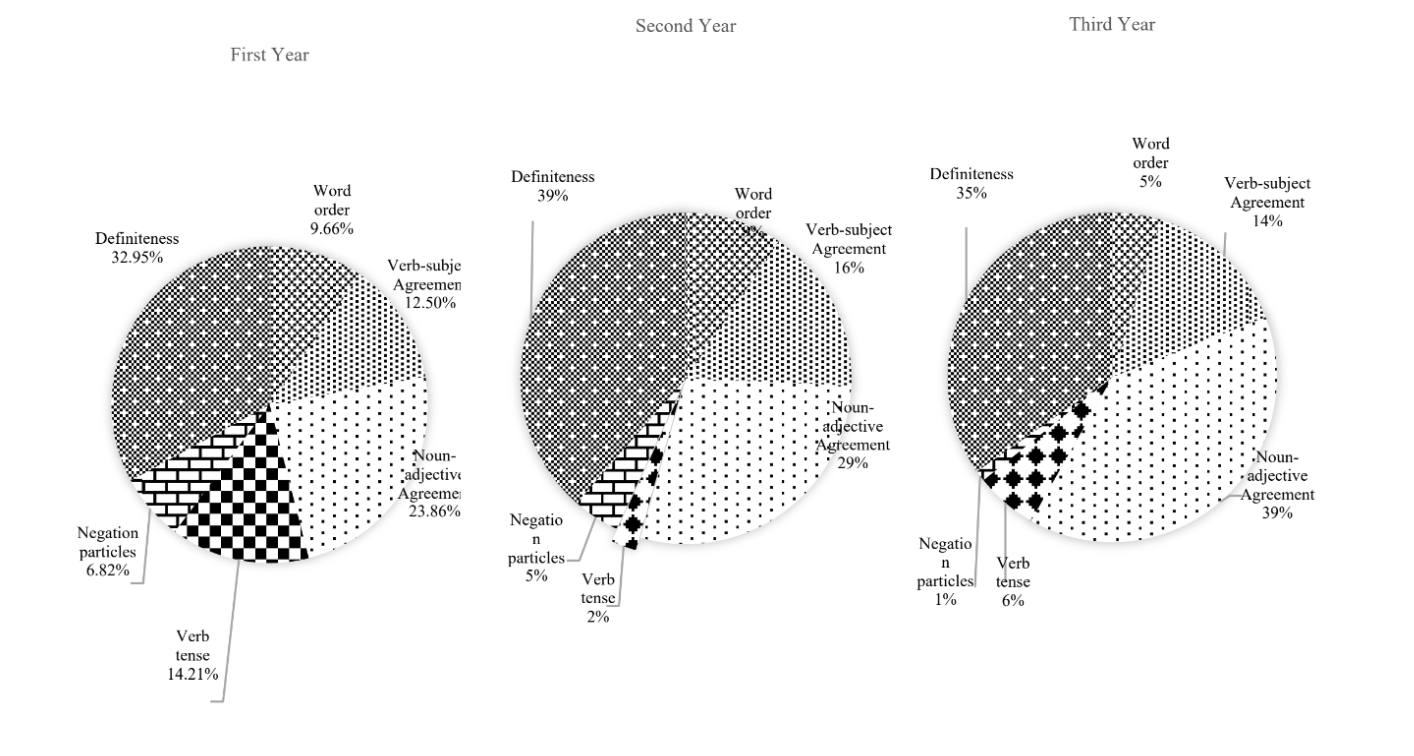
Figure 2: Total Grammatical Errors by Learners’ Level of Study
As mentioned in the previous section, six sub-categories were identified in the grammatical errors category: word order, subject-verb agreement, noun-adjective agreement, wrong verb tense, wrong use of negation particles, and definiteness. The most frequent subcategory of grammatical error was definiteness (10.5%) followed by noun-adjective agreement (9.5%), and verb formation (4.4%). In these three sub-categories, both first- and second-year students made fewer errors than third-year students. Yet the error types with lowest frequencies were negation particles (1.0%), verb tense (1.8%) and word order (2.2%), respectively. Figure 3 below shows the percentage of errors within the lexical errors category. The sub-categories identified in this group were: word choice, dialect substitute, connectors, vague meaning, and wrong use of prepositions:

Figure 3: Total Lexical Errors by Learners’ Level of Study

Figure 4: Total Spelling Errors by Learners’ Level of Study
To answer the second research question that explored whether the class level influenced learners’ errors, data were submitted to an Analysis of Variance. The results displayed no significant statistical differences between the three groups regarding both grammatical errors (F(2-27)=2.750, p=.082, η2=.169) and spelling errors (F(2-27) =1.057, p=.361, η2=.073). However, there was a significant statistical difference between the three groups regarding lexical errors (F(2-27)=4.432, p=.022, η2=.247). Post-hoc tests were followed, and they revealed that the significant difference between first-year learners and third-year learners was (p=.016). Table 4 shows the overall descriptive statistics for the error frequency by class level:
6 Discussion
This study investigated the writing errors produced by thirty L1 English learners of Arabic with the objective of helping educators understand error patterns, tailor their instruction and feedback to better address the needs of their students. The study’s data show that learners at all levels made more grammatical errors than lexical and spelling errors. This conclusion is in accordance with results shown in previous studies (e.g. Sutrisno 2018), which shows the persistence of grammatical errors despite the different target languages. Among the grammatical errors, our data also indicate that one of the main problems for learners at all levels was definiteness, not only within the category of grammatical errors, but also throughout all categories of errors. Definiteness accounted for more than 32.0% of errors in the grammatical error category and more than 15% of total errors. These numbers signify that the grammatical genitive construction in Arabic represents one of the main challenges of L1 English learners’, as does the definite article for Arabic nouns in those cases in which English does not use it. It is therefore recommended that instructors create activities that emphasise these aspects of Arabic from year one on, and that they continue addressing these concepts in subsequent years.
Noun-adjective agreement and subject-verb agreement were other grammatical sub-categories that constituted a significant percentage of the errors learners’ made. This was expected, as there is no adjective declension in English, and the concept of non-human-plural agreement in Arabic is absent in L1 English learners’ mother tongue. It is interesting to point out that both third-year and second-year learners made more noun-related errors (39.2% vs 28.8%) than verb-related errors (20.4% vs 18.66%). By contrast, first-year learners displayed the opposite pattern since they made more verb-related errors (26.7%) than noun-related errors (23.8%). Remarkably, this finding confirms previous studies with other languages, including English (e.g., Mariko 2007). Despite the differences between English and Arabic, lower-level learners were associated with verb errors, while higher-level learners were more closely associated with nominal errors. This indicates that this phenomenon may be a common developmental pattern rather than a language related one.
Among the lexical errors, word choice was the subcategory with the highest percentage, i.e., above 15.0% (Figure 3) within the lexical category and 5.7% within the total errors made. A possible explanation for the high number of errors in this subcategory is learners’ access to on-line translators, such as Google Translate. It was noticed that instead of looking up a word in their textbooks, students who are unfamiliar with it often use translators, which usually provide them with a list of terms. Most learners choose an item from the list without knowing whether the word fits the context of the sentence in which they want to use it. With the development of AI, machine translation tools – while helpful in many situations – have also grown more difficult for educators to utilise effectively into their pedagogical frameworks. A strategy needs to be found to address the increased dependency that many learners seem to have towards on-line translators. Ideally, instructors should try to force learners to limit the use of these translators and stress the importance of using the vocabulary learned in class, although recent studies have shown that this is a non-realistic approach (e.g. Chompurach 2021).
Another lexical subcategory that represented a major challenge to learners was prepositions. Prepositions accounted for between 21.0% and 37.0% (Figure 3) of the errors within the lexical category. Interestingly, the data in this study show that the higher the language level of the learners, the more mistakes they made in the field of prepositions: 21.6% (first-year learners), 27.8% (second-year learners), and 36.3% (third-year learners). A possible explanation for the difficulty that prepositions represent for learners of all levels is that there is no direct correspondence between prepositions as used in English and in Arabic, so there is no chance for students to transfer their use from one language to the other.
Like prior research on writing errors (Sermsook, Liamnimitr & Pochankorn 2017, Sawalmeh, 2013), our study found that spelling, which accounted for more than 18,1% of the total number of errors, was one of the most common errors made by learners at all levels. While third-year learners spelled words with an average accuracy of 63.5%, second-year learners’ spelling accuracy was lower (57.2%). However, the spelling average accuracy of first-year learners was the highest (79.2%). This relatively high frequency of spelling errors could be expected. In the first-year, most learners’ knowledge is based on memorised phrases that they often repeat. Moreover, first-year learners’ knowledge of the Arabic language is very limited, and they often adapt what they hear to a simplified system of writing. For example, they write the tanwin fatha sound /an/ using the letters alif nun, and they sometimes substitute emphatic letters with non-emphatic ones and vice versa. The reasons why higher-level learners produce spelling errors is not as clear as that. Emphatic letters still constitute a source of errors, but typographical errors associated with the keyboard placement of certain letters may also contribute to misspellings. On the other hand, composing an essay on a computer may artificially reduce the number of a learner’s spelling errors as many word processors automatically correct or mark spelling errors.
Comparing learners’ errors in writing across the three different class levels, a correlation between class level and certain lexical error sub-categories was found. There was a significant statistical difference between first- and third-year learners in relation to lexical sub-categories such as connectors (p=<0.001). This is an interesting finding that suggests that some writing errors may have similar developmental patterns, while others may differ across class levels. Specifically, some errors do not diminish or vanish for L1 English learners during their Arabic language acquisition and development, and this is an aspect which can be investigated further in future research.
Unlike findings of previous research (e.g. Wang 2003), however, this study found that third-year learners made more errors than the two other groups. One explanation could be that advanced learners often experiment with more complicated vocabulary, sentence structures, and colloquial expressions, which raises the risk of making errors. Conversely, first- and second-year students may choose to stick to safer, simpler language, which lowers the likelihood of errors. Another explanation could be that third-year learners, who are more advanced than the other two learner groups, may put more emphasis on communicating difficult concepts and information than proper grammar. That is, rather than being as concerned with language accuracy, their focus might be diverted to structuring ideas and arguments using their cognitive resources. Third-year students may also believe they are competent enough and not devote as much effort to editing and rewriting their work, which could result in errors that go overlooked. Learners' errors when writing in Arabic are influenced by their ability to write in their native language.
The results of this study were valuable, since they offered important insights into the kind of errors that students often made. By highlighting these errors, the study contributed to a better understanding of the unique difficulties that learners of Arabic encounter and provided invaluable recommendations for improving teaching methods that explicitly target these errors. Although the results confirmed the difficulties that learners faced when producing the grammatical genitive construction in Arabic, other errors were not as dominant as expected, such as the use of different negation particles. The researchers' experience as Arabic language teachers suggested that the different particles used in negation would be a challenge for L1 English learners of Arabic, especially at higher levels. The data, however, revealed that third-year learners made fewer negation errors (46,2%) than both first- (3.1%) and second-year learners (2.0%). The higher learners’ proficiency was, the fewer negation errors they made. Moreover, contrary to our expectations, lower-level learners made fewer errors in prepositions (21.5%, 27.8%) than third-year learners (36.2%).
The analysis of learners’ errors is noteworthy since most scholars interested in the issue are educators as well, and the results of this study may have a direct impact on the classroom. Therefore, this research is best understood not as a final and static determination but rather as a cyclical and iterative process in which its data, analysis, and conclusions may affect future instruction and learning outcomes, generating new data. Educators may adjust instruction material based on this study, and this ideally would reduce the number of errors that learners produce.
Moreover, the results offer insights that may increase foreign language educators and textbook writers’ awareness of common writing errors made by L2 learners in universities in the United States. For example, the results obtained can be used to help classroom instructors and textbook authors find pedagogical answers to minimise learners’ errors in writing at different language levels. Remedial materials can also be created based on the frequency of errors. The findings also display a relatively similar pattern for the developmental sequences for acquiring a second language that includes the silent period, formulaic speech and structural and semantic simplification. According to Ellis (1982), L1 and L2 learners tend to apply structural and semantic simplifications in their developmental stage which involves deleting grammatical functions (e.g. articles) and content words (e.g. nouns and verbs). This could explain the number of errors made by English learners of Arabic at different stages of exposure to the Arabic language in the current study. Third-year learners, for example, were more advanced than the other two groups. That is, they started to move away from the memorised structures and rely more on themselves producing language utterances, therefore making more mistakes. For example, noun-adjective agreement errors for third-year learners were 39.1%, compared with the 23.8% of first-year learners and the 29.3% of second-year learners. Moreover, to acquire grammatical morphemes, previous L2 research studies (e.g. Brown 1973) display that there is a sequence of acquisition for function words in the respective L2 languages including noun and verb inflections, articles and prepositions. Language rules are acquired in a more or less predictable order, and knowing the developmental stages that learners go through in their acquisition of writing in an L2 is beneficial (Krashen 1982). Not only does it help teachers to arrange the order of content presented to learners, but it also helps teachers understand why learners have problems acquiring certain features of the target language. Additionally, the results of this study give rise for L2 instructors to rethink their assumptions or potential misconceptions about where the most common errors lie. Educators working with intuition rather than data may concentrate on certain grammatical or vocabulary issues that are not truly the source of most writing errors in quantitative terms. The negation particles are an example of this. Though certainly challenging for learners, the percentage of occurrence of errors relating to negation particles was lower than the two researchers expected.
The data in this study cannot be generalised for three key reasons:
The study is based on the analysis of a small sample of essays (n=30) that were written unsupervised as the writing assignments were not part of the class activities. Instead, these assignments were part of language projects that students completed away from class.
Comparing writing assignments with different specifications and length presents another problem. For example, third-year students created a research paper that included 1000 words, whereas first- and second-year students wrote 200 words only. The higher complexity and length obviously increased the number of errors, and comparison between classes may not always be possible or indicative of students’ fluency.
Unlike the first-year learners, the students in the second and third-year produced the writing samples typing in Arabic, which is a skill in itself. Unfamiliarity with the keyboard may have produced additional errors that might not have occurred in handwritten essays. It is also unclear how errors in writing in Arabic relate to the learners’ ability to write in their own mother tongue.
Future research may address this issue together with the effect of task type and length of study on learners’ errors in writing. Future research can also test students' proficiency levels before collecting samples and grouping them accordingly; this was not feasible in the current study, which employed the class level instead. Additional research on topics, such as acquisition order and sequence and the role of feedback by instructors as well as the relationship between learners’ errors in writing and speaking could provide a deeper understanding of the process of writing in Arabic. Such investigations could help educators better inform their students and possibly result in the development of remedial teaching materials that are more widely applicable.
8 Conclusion
This study was designed to explore the types of errors in writing Arabic made by L1 English learners. Thirty essays from three different class levels were analysed, and it was found that lexical errors were the most common type of errors, followed by grammatical errors. Students found it difficult to communicate their ideas clearly because they struggled with word choice and used inappropriate or incorrect vocabulary. This suggests that although students may have a basic grasp of Arabic grammar, they still lack lexical knowledge and contextual application abilities. These findings highlight the need for teaching strategies that prioritise vocabulary acquisition, while also focusing on the complexity of word use in many contexts, to enable students to use Arabic more fluently and efficiently.
The findings also show the complex relationship between language transfer, grammatical problems and the complexities of second language acquisition. The second most common errors identified were grammar-related, such as verb conjugation, gender agreement, and the usage of prepositions, all of which varied significantly between English and Arabic.
Among the subcategories of writing errors, definiteness was found to be the highest and incorrect use of negation particles the lowest. These errors reflect the learners' inability to comprehend Arabic grammar rules, with many relying on native language patterns. These findings highlight the need for specialised instruction that directly addresses these areas of difficulty, using a contrastive approach to assist learners in navigating the differences between English and Arabic.
Appendix
Sample instructions for first year learners:
Write a 200-word essay on any topic you like using the vocabulary and grammar of the lessons covered in class.
Sample instructions for second year learners:
Write a 200-word essay about the theme of الزواج in the US. You may focus on any of the following:
فكرة تأسيس البيت
مشكلة السكن عند الشباب
الزواج في بيت العائلة
Sample instructions for third year students
Write a research paper which explores a topic of your choice related to Arabic literature. The paper should be no less than 1,000 words.
References
Al-Ani, S. H. (1972). Features of Interference in the Teaching of Arabic Composition. An-Nashra, 5/6, 3–13.
Alasfour, A. S. (2018). Grammatical Errors by Arabic ESL Students: An Investigation of L1 Transfer through Error Analysis (Unpublished doctoral dissertation). Portland State University.
Alkadi, S. H. (2015). English speakers’ common orthographic errors in Arabic as L2 writing system: an analytical case study. [Unpublished doctoral dissertation, Newcastle University]. ProQuest Dissertations Publishing.
Alosh, M. & Clark, A. S. (2010). Ahlan wa sahlan: functional modern standard Arabic for beginners (2nd ed.). Yale University Press.
Alosh, M. & Clark, A. S. (2013). Ahlan wa sahlan: functional modern standard Arabic for intermediate learners (2nd ed.). Yale University Press.
Amiri, F., & Puteh, M. (2017). Error analysis in academic writing: A case of international postgraduate students in Malaysia. Advances in Language and Literary Studies, 8(4), 141-145. http://dx.doi.org/10.7575/aiac.alls.v.8n.4p. 141.
Bjork, L., & Raisanen, C. (1997). Academic Writing: A University Writing Course. Lund, Sweden: Studentlitteratur.
Brown, R. (1973). Development of the first language in the human species. American Psychologist, 28(2), 97-106. https://doi.org/10.1037/h0034209.
Brustad, K., Al-Batal, M. & Tunisi, A. (2011). al-Kitāb fī taʻallum al-ʻArabīyah. A Textbook for Beginning Arabic. Part one (3rd ed.). Georgetown University Press.
Brustad, K., Al-Batal, M. & Tunisi, A. (2013). Al-Kitaab fii taʻallum al-ʻArabiyya. A textbook for intermediate Arabic. Part two (3rd ed.). Georgetown University Press.
Chompurach, W. (2021). “Please Let me Use Google Translate”: Thai EFL Students’ Behavior and Attitudes toward Google Translate Use in English Writing. English Language Teaching, 14(12), 23-35. https://doi.org/10.5539/elt.v14n12p23.
Corder, S. P. (1967). The significance of learner's errors. International Review of Applied Linguistics in Language Teaching, 5(4), 161-170.
Corder, S. P. (1974). Error Analysis. In J. P. B. Allen and S. P. Corder (eds.), Techniques in Applied Linguistics, (pp.122-154). London: Oxford University Press (Language and Language Learning).
Darus, S., & Subramaniam, K. (2009). Error analysis of the written English essays of secondary school students in Malaysia: A case study. European Journal of Social Sciences, 8(3), 483-495.
Ellis, R. (1994). The study of second language acquisition. Oxford: Oxford University Press.
Ellis, R., & Barkhuizen, G. (2005). Analyzing learner language. Oxford: Oxford University Press.
Gass, S. M. & Selinker, L. (2001) Second language acquisition: An introductory course. New Jersey: Lawrence Erlbaum Associates, Publishers.
Gedion, A., Tati, J. S., & Peter, J. C. (2016). A syntactic errors analysis in the Malaysian ESL learners’ written composition. Applied Linguistics and Language Research, 3(6), 96-104.
Holes, C. (2004). Modern Arabic structures and functions. Washington: Georgetown Press.
Krashen, S. (1982). Theory versus practice in language training. In R. W. Blair (Ed.), Innovative approaches to language teaching (pp. 15-24). Rowley, MA: Newburry House Publishers.
Lado, R. (1957). Linguistics across cultures. Ann Arbor: Michigan U.P.
Larsen-Freeman, D., & Long, M. H. (1991). An introduction to second language acquisition research. London: Routledge.
Mariko, A. (2007). Grammatical errors across proficiency levels in L2 spoken and written English. The Economic Journal of Takasaki City University of Economics, 49(3,4), 117-129.
Mitchell, T. F. (1962). Colloquial Arabic: The Living Language of Egypt. London: The English Universities Press.
Qaid, Y. A. & Ramamoorthy, L. (2011). A Study of Arabic Interference in Yemeni University Students’ English Writing. Language in India, 11(4), 28-37.
Rammuny, R. M. (1976). Statistical study of errors made by American students in written Arabic. Al-’Arabiyya, 9(1/2), 75-94.
Rustipa, K. (2011). Contrastive analysis, error analysis, interlanguage, and the implication of language teaching. Ragam Jurnal Pengembangan Humaniora, 11(1), 16-22.
Saville-Troike, Muriel. (2012). Introducing Second Language Acquisition (2nd Edition). Cambridge: Cambridge University Press. https://doi.org/10.1017/CBO9780511888830.
Sawalmeh, H. M. (2013). Error analysis of Written English essays: The case of students of the preparatory year program in Saudi Arabia. English for Specific Purpose Word, 14(40), 1-17.
Selinker, L. (1972). Interlanguage. International Review of Applied Linguistics in Language Teaching, 10(3), 209-231.
Sermsook, K., Liamnimitr, J., & Pochakorn, R. (2017). An analysis of errors in written English sentences: A case study of Thai EFL students. Canadian Center of Science and Education,10(3), 101-110. http://dx.doi.org/10.5539/elt.v10n3p101.
Shehata, A. (2018). Native English speakers’ perception and production of Arabic consonants. In M. T. Alhawary (Ed.), Handbook of Arabic second language acquisition (pp. 56–69). New York: Routledge.
Shehata, A. (2024). Learners’ perceptions of Arabic consonant contrasts: Gender and learning-context effects. Languages 9:77. https://doi.org/10.3390.
Sutrisno, B. (2018). Error analysis on English writing skill for the first semester students. Journal of English Language and Literature (JELL), 1(1), 1-20. https://doi.org/10.37110/jell.v1i01.10.
Uthman, M., & Abdalla, A. (2015). An analysis of common grammatical errors made by Saudi university students in writing. Express, an International Journal of Multi-Disciplinary Research, 2(3), 1-13.
VanPatten, B., & Benati, A. G. (2010). Key terms in second language acquisition. New York: Continuum International Publishing Group.
Wahba, K. M., Taha, Z. A., & England, L. (2013). Handbook for Arabic language teaching professionals in the 21st century. New York: Routledge.
Wang, L. (2003). Switching to first language among writers with differing second-language proficiency. Journal of Second Language Writing, 12, 347-375. https://doi.org/10.1016/j.jslw.2003.08.003.
Whitman, R. L., & Jackson, K. L. (1972). The unpredictability of contrastive analysis. Language Learning, 22(2), 29-41.
Xiaoli, B. (2015). Analysis on lexical errors in college English writing. Canadian Social Science, 11(12), 127-130. http://dx.doi.org/10.3968/7775.
Zafar, A. (2016). Error analysis: A tool to improve English skills of undergraduate students. Procedia - Social and Behavioral Sciences, 217, 697-705. https://doi.org/10.1016/j.sbspro.2016.02.122.
Authors
Asmaa Shehata, Ph.D.
Assistant Professor
The University of Mississippi
Department of Modern Languages
103 Howry Hall
University, MS 38677-1848 662-915-1701
Email: akshehat@olemiss.edu
Amaya Martin
Arlington Public Schools
2110 Washington Blvd Arlington, VA 22204
703-228-4220
Email: amaya.martin@apsva.us
___________________________________________________
(1) Interlanguage Theory was first introduced by Larry Selinker in 1972 to refer to the uniqueness of the new language system created by L2 language learners that is different from both L1 and the target language. Thus, L2 learners do not automatically copy the roles of their native language when learning a new language.