
Journal of Linguistics and Language Teaching
Volume 8 (2017) Issue 2 (PDF)
pp. 209-232
A Corpus-Driven Investigation
into Monosyllabic and Disyllabic Tone Errors
by German Learners of Chinese
Yi-Ling Lillian Tinnefeld-Yeh (Saarbrücken, Germany)
Abstract (English)
Adopting a corpus-driven approach, the present study investigates German students’ production of monosyllabic and disyllabic tones in a beginner’s class. The study demonstrates how texts from target resources can be processed to document errors as well as how tables of monosyllabic and disyllabic tones with example entries can be compiled for methodological use in a classroom setting. Common tone errors made by German students are identified and presented in their occurring contexts, using the corpus analysis tool AntConc. The statistic results of the study show that the falling tone (Tone 4), as a monosyllabic tone and particularly as the second syllable in disyllabic tones, presents the most challenging one for students. Tone 3 (i.e. the falling-rising tone), is the most problematic one when residing in the first syllable of disyllabic tones, particularly in the combination of Tone 3 and Tone 4.
Key words: Corpus-driven investigation, tone errors, German learners of Chinese
Abstract (Deutsch)
In dem vorliegenden Artikel wird im Rahmen eines korpusgeleiteten Ansatzes die Realisierung der Töne in monosyllabischer und bisyllabischer Ebene durch deutsche Studierende in einem Chinesisch-Anfängerkurs untersucht. Es wird aufgezeigt, in welcher Weise Texte des zielsprachlichen Korpus für die Dokumentation von Fehlern verarbeitet und wie Tonkombinationstabellen mitsamt von Beispieleinträgen für didaktische Zwecke zusammengestellt und genutzt werden können. Häufig auftretende Tonfehler deutscher Studierender werden unter Berücksichtigung des Korpusanalyseinstruments AntConc identifiziert und in ihrer jeweiligen Umgebung beschrieben. Die statistischen Ergebnisse zeigen, dass der vierte (fallende) Ton in monosyllabischer Verwendung und in der zweiten Silbe bisyllabischer Verwendung für deutsche Studierende am problematischsten ist. Der dritte (fallend-steigende) Ton ist in der ersten Silbe bisyllabischer Wörter – besonders in Kombination von drittem und viertem Ton – der am schwierigsten zu realisierende.
Stichwörter: Korpusgeleiteter Ansatz, Tonfehler, deusche Chinesischlerner
1 Introduction and Background Information
When being asked the question of what the difficulty of speaking mandarin Chinese lies in, researchers (Lin 1985, Tong, et al 2015), experienced teachers and students of Chinese would give this answer in unison: the tones of the language. In standard Chinese, there are four different lexical tones and a neutral tone (Chao 1933). As Li (2006: 209) states, “Lexical tones are pitch patterns that serve to provide contrasts in word meanings.” To put it more precisely, tones are the changes of pitch of individual sounds that give different meanings to the same syllable, thus indicating different Chinese characters, i.e. the Chinese written signs.
As this unique language phenomenon is comparatively new and unacquainted to Western learners, it presents a challenge to both teachers and students, and in many cases, an obstacle to students’ attempts to improve their pronunciation accuracy, even at the intermediate and advanced levels (Orton 2013). This is to say that the teaching and learning of tones should be paid special attention to from the very beginning (Cao 2016).
As stated above, there exist five tones in Chinese. Yet, the question of which tones appear to be the most challenging ones to Chinese learners of different language backgrounds is a promising topic to explore, in that it gives teachers valuable insight into leaners’ problems of tone perception and production.
Figure 1, taken from Jin Zhang’s webpage at the Massachusetts Institute of Technology (http://web.mit.edu/jinzhang/www/pinyin/tones/; 23-05-2017), captures a laconic picture of the pitch contours of Mandarin tones:
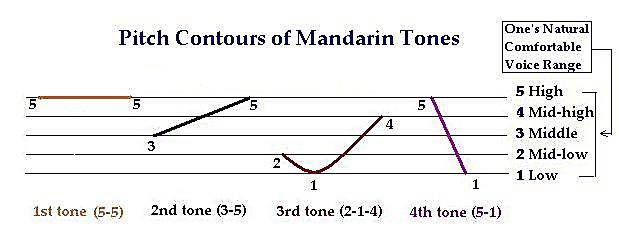
Figure 1: Pitch Contours of Mandarin Tones (created by Jin Zhang)
The fifth tone is not presented since it is a soft, neutral one. Illustration 2, generated by the author, using Speech Analyser - a speech analysis toolkit - yields the visual forms of all the five tones:
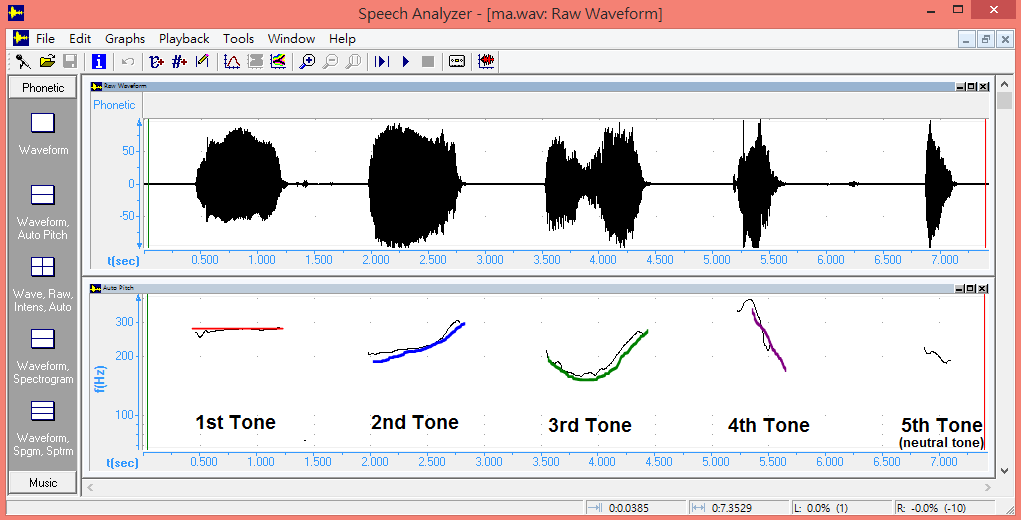
Figure 2: Pitch Contours of Mandarin Tones (generated by the author, using Speech Analyser)
For the past few decades, numerous studies (White 1981, Lin 1985, Miracle 1989, Shen 1989, Wang, Spence, Jongman & Sereno 1999, Klein, Zatorre, Milner & Zhao 2001, Wang, Jongman & Sereno 2003, Guo & Tao, 2008, Lee, Tao & Bond 2010, Yang & Chan 2010, Hao 2012, Almelaifi 2013, He, Wang & Wayland 2016, Li & Dekeyser 2017) have been conducted to explore the acquisition and training of tones of English-speaking learners of Chinese. However, a comparatively low number of studies had been carried out to explore this issue on German-speaking learners of Chinese before the millennium. A literature review suggests that relevant research issues on the tone performance of German speakers began drawing attention from researchers, starting from Year 2004.
Such studies (Hunold 2004, Tillmann & Pfitzinger 2004, Ding, Jokisch & Hoffmann 2010, Peng, Gang et al. 2010, Hussein, Hussein et al 2011, Ding, Hoffmann & Jokisch 2011, Ding 2012, Brengelmann, Cangemi & Grice 2015), coordinated by various researchers in different teams, unquestionably shed light on the elucidation of the phenomenon of tone-related errors of learners of Chinese in a German-speaking context. One of the salient findings of these studies lies in the frequencies of different tonal errors that German speakers make at the monosyllabic and the dissyllabic level as well as the sentence level. In the framework of pedagogical implications, though being hinted to in these papers, little explicit mention has been made with regards to the issue as regards the question of how these findings can be technically and pedagogically applied to teaching in the foreign language classroom. Moreover, most researchers have explored the tone realisation of German speakers by utilising speech processing technology, using software for acoustic-phonetic speech analysis, such as Praat in Ding’s (2012) and in Brengelmann, Cangemi & Grice’s (2015) study.
To approach this issue from another perspective, it may be plausible to conduct an investigation into learners’ tone errors in form of a learner-language output corpus and to carry out a systematic study of these errors in aid of a corpus analysis tool. Based on a 14-million-character corpus taken from Chinese newspapers, Chen, Tseng, Huang & Chen (1993) conducted a comprehensive research on the distributional properties of Chinese. One of their findings was that monosyllabic and disyllabic word tokens take up to 96% of a databank of 9,529,233 segmented words (Chen, Tseng, Huang & Chen 1993: 83). With this in mind, the present study focuses on the monosyllabic and the disyllabic level.
Set in the context of a Chinese language class for beginners at a German university of applied sciences, the present study aims to:
- explore the possibility of utilising a corpus-analysis tool for the teaching and learning of Chinese tones,
- investigate the phonological production of Chinese monosyllabic and disyllabic tones by German learners,
- identify commonly made errors,
- discuss potential causes and reasons, and
- discuss how the findings can contribute to the teaching of Chinese.
The findings of this study will hopefully be of benefit to teachers’ instruction efficiency and to students’ learning outcome.
2 Data Collection, Processing, and Research Method
The databank of the study is comprised of the oral production of the end-of-semester recording task of the author’s students in her Chinese courses for beginners at Saarland University of Applied Sciences in Germany in the 2014 summer semester as well as the 2014-2015 winter semester. Students were requested to record their recitations of two dialogues in the first five lessons, totalling 10 texts, from New Practical Chinese Reader (2005), one of the most widely-used course books in the world. Students were then asked to send the audio files of their recordings to their instructor, who was also the researcher and the author of the present article, after having completed this task. Altogether, 15 students completed ten audio clips of the dialogue each. In total, 150 audio clips were collected to compile the databank of this study.
All the subjects of this study either are of German nationality or grew up in Germany. One subject has dual French-German citizenship. The following table provides an overall view of students’ backgrounds:
- 13 of 15 students were female; only two were male
- the majority of student were from the Business school of the university
- all the subjects spoke English, with an overwhelming majority (13 students) having at least a satisfactory command of French:
Student
|
Gender
|
Major
|
Language Competence
|
A.
|
F
|
International Tourism Management
|
English, Spanish
|
K.
|
F
|
International Tourism Management
|
English, French, Italian
|
S.
|
F
|
International Tourism Management
|
English, French, Italian
|
T.
|
F
|
International Tourism Management
|
English, French, Spanish, Vietnamese
|
N.
|
F
|
International Tourism Management
|
English, Spanish
|
An.
|
F
|
International Business Administration
|
English, French, Spanish
|
I.
|
F
|
International Business Administration
|
English, French
|
R.
|
F
|
International Business Administration
|
English, French, Spanish, Albanian
|
F.
|
F
|
Management Sciences
|
French, English
|
J.
(German-French)
|
F
|
Management Sciences
|
French, English, Spanish
|
M.
|
F
|
Management Sciences
|
French, English
|
S.
|
F
|
Management Sciences
|
English, French, Dutch, Spanish
|
V.
|
F
|
Business Administration
|
English, French, Spanish
|
D.
|
M
|
Business Administration
|
English, French
|
M.
|
M
|
Electronics
|
French, English
|
Table 1: Students' Backgrounds
To envisage the words whose tones were not pronounced correctly in their language surroundings, a corpus approach, using a concordance-program tool to analyse the data files, was adopted. This approach allows researchers “to see the word or concordance in its ‘natural habitat’, the original text, in order to re-contextualise how it is used”. (Parise 2015). Based on a comprehensive list of concordancers (accessed on 25-10-2015), search engines and text-analysis tools compiled by one of the leading corpus linguistics researchers, David Lee, the top three software and tools that are the most expedient for users in general are AntConc, WordSmith Tools and MonoconcEsy (Lee 2015 (1)).
The data analysis tool employed in this study was hence AntConc, “a freeware corpus analysis toolkit for concordancing and text analysis” developed by Laurence Anthony of Waseda University in Tokyo, Japan (Anthony 2014). From the author’s personal point of view, its user-friendly interface makes it indeed more pleasant to work with AntConc than other corpus analysis tools. Nevertheless, despite the various functions provided by AntConc and despite the fact that it can even be used for the analysis of Japanese and Chinese written texts, it cannot decode the tone mark that takes the place above the vowel of a syllabus, e.g. mā, má, mǎ, mà, ma. Confronted with this problem, the author processed the transcripts of the ten dialogue texts preceding the work of the data input, herself.
Below is an extract of a dialogue text taken from Lesson 3 of the target course book. Each line in the dialogue is presented with Chinese phonetic scripts, i.e. Pinyin, on its corresponding line of the Chinese written characters:

Taking the previous instance - mā, má, mǎ, mà, ma - again as an example, ā (high level) represents the 1st tone, á (rising) the 2nd, ǎ (falling-rising) the third, à (falling) the 4th and a represents the neutral tone, the 5th tone. All the tone marks in the content lines of the model dialogues were, thus, replaced with Arabic numbers 1, 2, 3, 4, 5. Below is an example:

Other than this, to identify the error at the respective syllable level rather than at the word (2) level, words 词cí such as wǒmen ('we'), lǎoshī ('teacher') and Zhōngguó ('China') were manually segmented with a blank being inserted in between the syllables to have the individual syllable come into place. This being done, the author started marking tone errors on the word files of the transcripts while listening to students’ voice recordings. In the course of pre-data processing, the tone errors were tagged with a hash mark #. An example is provided below:
Other than this, to identify the error at the respective syllable level rather than at the word (2) level, words 词cí such as wǒmen ('we'), lǎoshī ('teacher') and Zhōngguó ('China') were manually segmented with a blank being inserted in between the syllables to have the individual syllable come into place. This being done, the author started marking tone errors on the word files of the transcripts while listening to students’ voice recordings. In the course of pre-data processing, the tone errors were tagged with a hash mark #. An example is provided below:
After the processing of all the word files of transcripts in which tonal errors found in students’ voice recordings were tagged, the files were saved in a plain text format (txt.) for AntConc to process:

Figure 3: Plain Text Format of the Files
The hash mark #, which, as it happened, functions as one of the seven wildcards for word searching in AntConc, was then replaced with , using the Replace function, to indicate tone errors, as exemplified in the three snapshots below:

Figure 4: Indication of Tone Errors
This having been done, the prerequisite of all the data being processed was fulfilled. A corpus databank of 150 tagged transcripts of 15 students’ voice recordings of ten dialogue texts was built up.
3 Methodology
Due to the fact that the tone marks of all the words in the model dialogues had been replaced with Arabic numbers, monosyllabic entries (including the single words zì in the multi-syllable words cí) could be efficiently located, using AntConc, by keying in the asterisk mark (*) as the wild card plus the corresponding Arabic number to each tone, and consequently, a categorical list of monosyllabic tones could be easily compiled, using the corpus files of the processed transcripts of the 10 model dialogues from the course book. Below is a screenshot (Figure 5) which shows the 1st tone monosyllabic entries being called up at one click, with the targets displayed in the middle:
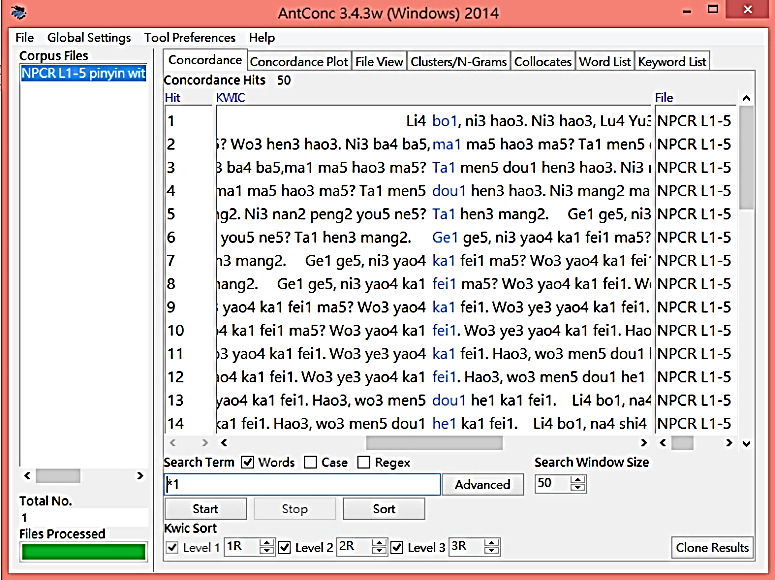
Figure 5: Search for 1st-Tone Monosyllabic Entries, Using AntConc
Likewise, a similar procedure was applied to the search for disyllabic words, phrases and structures. By entering *1 (plus a blank space in-between) *1, the concordance lines show all the possible targets (Figure 6). By scrolling down these lines, meaningful units such as kāfēi (coffee), yīshēng ('medical doctor') and cāntīng ('restaurant', 'cafeteria') were picked up to compile a table (Table 2) with different tone combinations:

Disyllabic
Tones
|
Tone 1 (ā)
|
Tone 2 (á)
|
Tone 3 (ǎ)
|
Tone 4 (à)
|
Tone 5 (a)
| |
Tone 1 (ā)
| ||||||
Tone 2 (á)
| ||||||
Tone 3 (ǎ)
| ||||||
Tone 4 (à)
| ||||||
Table 2: Template Table of Tone Combinations
After the vocabulary tables had been built, an ensuing search, using the corpus files of the tagged transcripts of the 15 students’ oral production, was conducted to find the numbers of the total occurrences of each tone. Subsequently, the search was executed by entering an asterisk *, plus the corresponding Arabic number, plus as the search entry for the items of each target tone which was mispronounced (Figure 7):
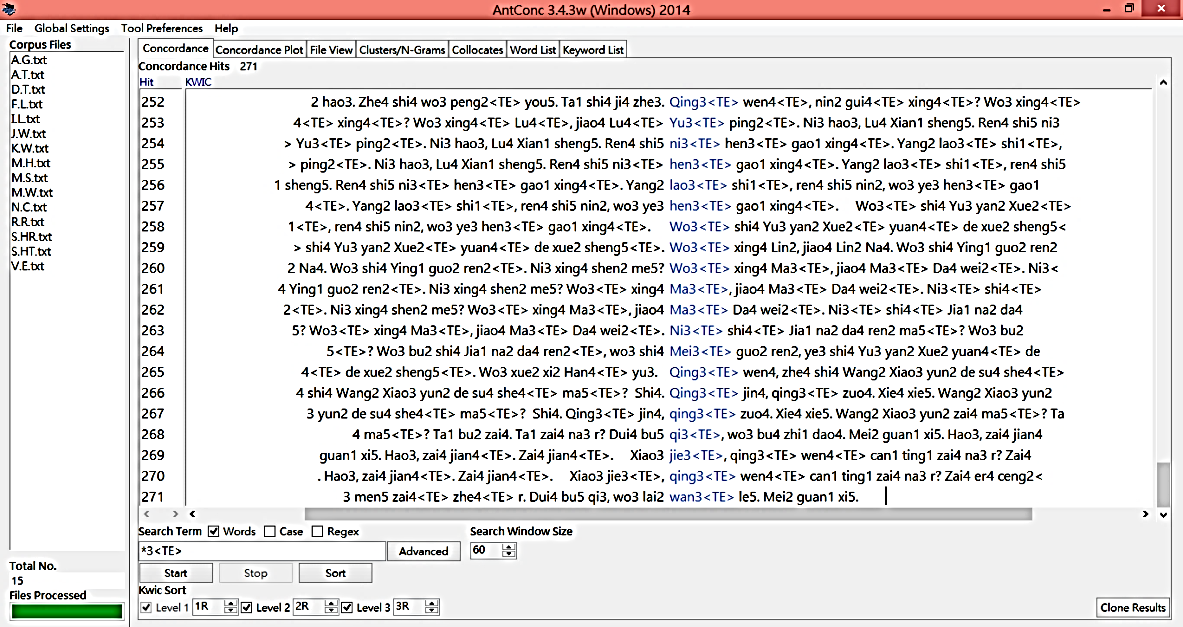
Figure 7: Search for 3rd Tone Errors, Using AntConc
4 Analysis and Findings
4.1 Monosyllabic Tones
The statistic results of the search are presented in the ‘error-occurrence percentage’ rubric in the Table 3:
Monosyllablic
Tone
|
Tone 1 (ā)
|
Tone 2 (á)
|
Tone 3 (ǎ)
|
Tone 4 (à)
|
Tone 5 (a)
|
dōu
hē
tā
mā
...
|
máng
shéi
guó
rén
nín
Lín
Chéng
Yáng
Wáng
céng
...
|
nǐ
hǎo
wǒ
hěn
yě
qǐng
nǎ(r)
...
lǎosī
duìbuqǐ
Mǎ Dàwéi
Lù Yǔpíng
Wáng Xiǎoyún
Měiguórén
|
shì
bù
yào
shì
nà
zhè
jìn
wèn
guì
xìng
jiào
Lù
zuò
zài
...
|
ma
ne
le
...
bàba
māma
gēge
dìdi
nǎinai
péngyou
jìnlai
méiguānxi
duìbuqǐ
| |
Error /
Occurrence
(in percent)
|
108/750=
14.4 %
|
172/960=
17.9%
|
271/1665=
16.3%
|
323/1530=
21.1%
|
99/600=
16.5%
|
Table 3: Students’ Errors in Five Monosyllabic Tones (3)
The findings reveal that the subjects of the study have difficulties with all the five tones. Upon closer inspection, however, it was found that Tone 4, the falling tone (21.1%), was more problematic for students than the other four tones – Tone 2 (17.9%), Tone 5 (16.5%), Tone 3 (16.3%), Tone 1 (14.4%). In contrast to Li & Thompson’s findings (1977) as well as Tsai’s (2011) statement that Tone 3 is generally considered as the most challenging one for learners of Chinese, Tone 4 emerged to be the one that required more attention from both teachers and students. A similar finding was indicated in Shen’s (1989) investigation in which she analysed the tonal errors made by American learners of Chinese. Her results showed a high percentage of errors (55.6%) for Tone 4, followed by Tone 3 (16.7%), Tone 5 (16.5%), Tone 1 (9.4%) with Tone 2 (8.9%) being the least cumbersome ones. However, the statistic results of the present study on different tones are not as distinctive as Shen’s findings.
Attesting to Shen’s research results, the findings of this study prove that the accurate production of Tone 5 by learners is not an easy task for German students of Chinese. It is surprising to note that Tone 5 (16.5%) occurred to be a demanding one for learners. As a neutral, unstressed tone, Tone 5 was first considered to be the least problematic one by the author. A closer inspection of the word entries and the audio data, however, reveals two important aspects:
- The word ma, the Chinese question particle for yes-no questions, placed at the end of an utterance to form questions, was frequently misprounced as the 2nd-rising tone: in the present study, all those students who failed to pronounce ma correctly all pronounced it as má. This phenomenon may boil down to the natural tendency of European speakers towards the rising of intonation at the end of a question utterance.
- In the cases of words such as māma ('mother'), bàba ('father'), where Tone 5 takes the second syllable of disyllabic tones, students tended to pronounce them as mǎmá, bǎbá. This might also be due to a negative interlanguage transfer.
With regards to the 2nd and the 3rd tones, no significant difference between the respective error percentages was found. The percentage of errors of monosyllabic words with the 2nd (rising) tone (17.9%) was slightly higher than that of those with the 3rd (falling-rising) tone (16.3%). A plausible explanation is the phenomenon of the prosodic application of the 3rd tone Sandhi: in the case of two 3rd tones neighbouring each other in a disyllabic sequence, for example nǐ hǎo (‘hello’), the first one changes into the 2nd tone - ní hǎo - so as to economise pronunciation efforts. That is, the first 3rd-tone word, when pronounced as Tone 2, in a Tone 3-Tone 3 combination is not and should not be counted as errors.
In addition, in a case when a 3rd tone is followed by a 4th or a neutral tone such as qǐngwèn (‘Excuse me, may I ask…’) and nǎinai (‘grandma’), the preceding 3rd tone loses its rising inflection, turning to be a low tone or a so-called half-third tone. This pronunciation rule has also been taken into account during the error-spotting procedure. In a word, the prosodic application of the 3rd tone Sandhi might explain why the error percentage of Tone-3 monosyllabic words is not as high as expected (4).
While the production of Tone 3 means a slide from the music scale 2 down to 1, followed by a rise to 3, the correct realisation of Tone 4 entails a swift drop from the music scale of 5 to 1 - a f0 range that is bigger than what European languages require for oral output. This is confirmed in Ding, Hoffmann & Jokisch’s study (2011), in which they analysed the perception and production of monosyllables by German learners of Chinese and found that their German subjects’ f0 range was much smaller than that of Chinese native speakers. The same phenomenon was also observed during the process of Mandarin tone and prosody acquisition among Australian university students (Zhang 2006) whose f0 range was found narrower when speaking English than when speaking Chinese.
However, at a close look at the corpus data to examine the errors of Tone 4 in their occurring contexts when ma (i.e. the Chinese question particle for yes-no questions) comes at the end of the sentence as a question particle, the concordance lines reveal that among 165 hits, 68 errors were found, i.e. a percentage of 41.2%. Yet, in cases of normal statements without ma being involved, the data bank displays 31 cases of errors among 435 occurrences of Tone 4 at the end of the sentence – i.e. a fairly low percentage of 7.1%. Again, this finding may be explained with German learners’ natural tendency to raise the intonation at the end of a question a phenomenon which is then transferred to Chinese, even in cases when the question ends with a word of the 4th (falling) tone followed by the question particle ma.
As well as German speakers’ tendency to raise the intonation when uttering a question, their natural predisposition to drop the pitch at the end of an utterance happens to be a positive language transfer when Chinese target sentences finish with a word of the 4th (falling) tone, which is acoustically comparable to unmarked patterns of declarative sentences at the end of German utterances.
4.2 Disyllablic Tones
Disyllabic words take a highly prominent share of the Chinese lexicon, according to Lü Shuxiang呂叔湘(1963), the founder of modern Chinese linguistic studies. Lü’s (1963) iconic, landmark work on the proportion of disyllabic words in Modern Chinese has been cited in the studies of numerous researchers’ works such as those by San (1999), Shi (2002) and Shibagaki (2014). Lü’s work on the top 3000 commonly-used words in standard Chinese clearly captured the distributional properties of modern Chinese. According to his studies on the percentages of disyllabic words in the categories of nouns, adjectives and verbs, the proportion of disyllabic nouns grasps more than 85%, that of disyllabic adjectives 69% and that of verbs 61%. This means that disyllabic words take up to 75%, a considerably high percentage that dominates the formation of modern common words of Chinese. Hence, Lü came to the conclusion that double-syllablisation (or bi-syllabification) exhibits a main prosodic tendency of modern Chinese. This means that some monosyllabic words such as hóu ('monkey') and hǔ ('tiger') were added another monosyllabic word – hóuzi (monkey) and lǎohǔ (tiger) – to make them form double-syllabic words for the mere prosodic purpose, while the meanings stay the same.
However, to investigate the pronunciation production of the learners, the present study not only took words of the above-mentioned parts of speech but also meaningful prosodic units (i.e. words, names or phrases in disyllabic chunks) such as Lín Nà (a female British student’s Chinese name), nǐ hǎo ('hello'), qǐng jìn ('Please come in'), èr céng ('the second floor'), nǐ ne ('How about you?') into consideration.
Exhibiting the entries of disyllabic words taken from the target resources, the table below presents the results of the statistic findings. Take the word gāoxìng for example (4+14+{2}/30=66.7%): among 30 occurrences, 4 cases of errors in the first syllable, 14 cases of errors in the second syllable, and 2 cases of errors of both syllables were found, the average error-occurrence percentage being 66.7%.
The overall statistic results of the study (Tables 4 and 5) demonstrate that disyllabic words with Tone 4 involved in the first syllable (i.e. 4+1, 4+2, 4+3, 4+4) or the second syllable (i.e. 1+4, 2+4, 3+4, 4+4) represented the highest relative ratios of mispronunciation:
Disyl-labic Tones
|
Tone 1 (ā)
|
Tone 2 (á)
|
Tone 3 (ǎ)
|
Tone 4 (à)
|
Tone 5 (a)
|
Error /
Occur-rence
(in percent)
|
Tone 1 (ā)
|
25.6%
|
13.3%
|
---
|
62.2%
|
20.0%
|
27.3%
|
Tone 2 (á)
|
---
|
0.0%
|
6.7%
|
55%
|
20.0%
|
31.5%
|
Tone 3 (ǎ)
|
37.5%
|
47.5%
|
15.0%
|
48.9%
|
23.3%
|
34.3%
|
Tone 4 (à)
|
55.6%
|
34.4%
|
46.7%
|
56.7%
|
20.0%
|
38.7%
|
Error /
Occur-rence
(in percent)
|
36.4%
|
34.8%
|
17.1%
|
54.6%
|
20.8%
|
Table 4: Percentages of Students’ Errors in All Tone Combinations from the Databank
Disyl-labic Tones
|
Tone 1 (ā)
|
Tone 2 (á)
|
Tone 3 (ǎ)
|
Tone 4 (à)
|
Tone 5 (a)
|
Error/
Occur-rence
|
Tone 1 (ā)
|
kāfēi
1+17/60=30.0%
yīshēng
1+4/15=33.3%
cāntīng
0+0/15=0.0%
|
Zhōngguó
2+3/30=16.6%
Yīngguó
0+1/15=6.7%
|
---
|
gāoxìng
4+14+{2}/30=
66.7%
zhīdào
1+6+{1}/15=
53.3%
|
māma
3+2+{3}/15=53.3%
gēge 1+4/30=16.6%
tāmen
0+0/15=0.0%
xiānsheng
1+2/15=20.0%
guānxi
5+0/30=16.7%
| |
23/90=
25.6%
|
6/45=
13.3%
|
---
|
28/45=
62.2%
|
21/105=
20.0%
|
78/285=27.3%
| |
Tone 2 (á)
|
---
|
xuéxí
0+0/15=0.0%
|
nín hǎo
1+3/60=6.7%
|
Lín Nà
0+13+{2}/30=
50.0%
xuéyuàn
0+22+{1}/30=
76.7%
bú shì
13+4+{3}/45=
44.4%
bú yòng
2+4+{2}/15=
53.3%
|
péngyou
10+2+{1}/45=
28.9%
xuésheng
0+2/30=6.7%
| |
---
|
0/15=
0.0%
|
4/60=
6.7%
|
66/120=
55.0%
|
15/75=
20.0%
|
85/270
=31.5%
| |
Tone 3 (ǎ)
|
lǎoshī
12+22+{11}/
120=37.5%
|
Měiguó
8+0/15=53.3%
Yǔpíng
3+12+{7}/45=
48.9%
yǔyá
7+6+{2}/30=
50.0%
Xiǎoyún
5+6+{1}/30=
40%
|
nǐ hǎo
1+11/105=
11.4%
kěyǐ
2+4/15=40.0%
|
qǐng jìn
6+0+{5}/30=
36.7%
qǐng zuò
4+0+{1}/15=
33.3%
qǐng wèn
4+7+{17}/45=
62.2%
|
nǐ ne
1+0+{1}/15=13.3%
wǒmen
10+1+{1}/60=
20.0%
nǎinai
3+1+{3}/15=46.6%
| |
45/120=
37.5%
|
57/120=
47.5%
|
18/120=
15.0%
|
44/90=
48.9%
|
21/90=
23.3%
|
185/
540=
34.3%
| |
Tone 4 (à)
|
Lìbō
0+23+{2}/45=
55.6%
|
bù máng
0+1/15=6.7%
wàipó
4+7+{3}/30=
46.7%
èr céng
1+4+{1}/15=
40.0%
Dàwéi
0+8+{2}/30=
33.3%
|
wàiyǔ
3+2+{3}/15=
53.3%
jìzhě
3+2+{1}/15=
40.0%
|
guì xìng
2+3+{8}/15=
86.7%
sùshè
0+3/15=20.0%
zàijiàn
1+7+{10}/30=
60.0%
|
bàba
1+0+{6}/15=46.7%
jìnlai
2+1/15=20.0%
rènshi
7+0/30=23.3%
xièxie
1+0/30=3.3%
| |
25/45=
55.6%
|
31/90=
34.4%
|
14/30=
46.7%
|
34/60=
56.7%
|
18/90=
20.0%
|
122/
315=
38.7%
| |
Error/
Occur-rence
|
93/255=
36.4%
|
94/270=
34.8%
|
36/210=
17.1%
|
172/315=
54.6%
|
75/360=
20.8%
|
Table 5: Error-Occurrence Percentage of the Entries of Tone
Combinations from the Databank (comprehensive figures)
The mean average of the percentages or errors were 38.7% and 54.6%, respectively. In the combination of Tone 1 and Tone 4, a percentage of errors of as high as 62.2 % occurred, followed by the combination of Tone 4-Tone 4 (56.7%), Tone 2-Tone 4 (55%), and Tone 3-Tone 3 (48.9%). These findings show that pedagogically, words of Tone-4 combinations such as gāoxìng ('happy', 'glad'), xuéyuàn ('college'), qǐngwèn ('May I ask?'), wàiyǔ ('foreign language') and zàijiàn ('goodbye') in Table 5, need more attention in the training of tone performance than words of the other tone combinations.
Another noteworthy point is the high rate of errors made with regards to Tone 3 (46.7%). The difficulty that German learners have with the Tone 3-Tone 2 combination such as Měiguó ('USA') and yǔyán ('language') in Table 5 attested to the findings of a research work carried out by Do et el. (2012). Funded by the German Ministry of Education and supported by the DAAD-NSC (Germany / Taiwan) and the DAAD-CSC (Germany / China), Do et al. (2012) pre-tested and post-tested seven German students of Chinese on their production of disyllables to evaluate a computer-aided pronunciation training system. One of their major findings is that the Tone 3-Tone 2 combination turned out to be the greatest challenge to students. An accuracy rate of 0% in the pretest and that of 57.14% in the posttest were reported.
Against this background, Tone 3 also appears to be a challenging one. The presumption as to whether Tone 3, when residing in the first syllable of a disyllabic chunk, plays a critical role in the correct tone performance will be further explored in this following section.
To have a micro view of the errors occurring in individual syllables of disyllabic chunks, a separate calculation of the percentages of errors in the first syllable and in the second syllable was conducted. The statistic results are presented in the two tables (Table 6 and Table 7) below:
Disyl-
labic Tones
|
Tone 1 (ā)
|
Tone 2 (á)
|
Tone 3 (ǎ)
|
Tone 4 (à)
|
Tone 5 (a)
|
Error /
Occur-rence
|
Tone 1 (ā)
|
2.2%
|
4.4%
|
---
|
17.8 %
|
12.4%
|
16.7%
|
Tone 2 (á)
|
---
|
0.0%
|
1.7%
|
19.2%
|
14.7%
|
13.0%
|
Tone 3 (ǎ)
|
19.2%
|
27.5%
|
2.5%
|
41.1%
|
21.1%
|
21.3%
|
Tone 4 (à)
|
4.5%
|
12.2%
|
33.3%
|
35.0%
|
18.9%
|
19.3%
|
Table 6: Total Error-Occurrence Percentages of the First Syllables in Disyllabic Tones
Disyl-labic Tones
|
Tone 1 (ā)
|
Tone 2 (á)
|
Tone 3 (ǎ)
|
Tone 4 (à)
|
Tone 5 (a)
|
Error/
Occurrence
|
Tone 1 (ā)
|
kāfēi
1/60=0.2%
yīshēng
1/15=6,7%
cāntīng 0/15=0.0%
|
Zhōngguó
2/30=6.7%
Yīngguó
0/15=0.0%
|
gāoxìng
4+{2}/30=20.0%
zhīdào
1+{1}/15=13.3%
|
māma
3+{3}/15= 40.0%
gēge
1/30=3.3%
tāmen
0/15=0.0%
xiānsheng
1/15=6.7%
guānxi
5/30=16.7%
| ||
2/90=
2.2%
|
2/45=
4.4%
|
---
|
8/45=
17.8%
|
13/105=
12.4%
|
25/285=16.7%
| |
Tone 2 (á)
|
---
|
xuéxí
0/15=0.0%
|
nín hǎo
1/60=1.7%
|
Lín Nà
0+{2}/30=6.7%
xuéyuàn
0+{1}/30=3.3%
bú shì
13+{3}/45=35.6%
bú yòng
2+{2}/15=26.7%
|
péngyou
10+{1}/45= 24.4%
xuésheng
0/30=0.0%
| |
---
|
0/15=
0%
|
1/60=
1.7%
|
23/120=
19.2%
|
11/75=
14.7%
|
35/270
= 13%
| |
Tone 3 (ǎ)
|
lǎoshī
12+{11}/120= 19.2%
|
Měiguó
8/15=53.3%
Yǔpíng
3+{7}/45= 2.2%
yǔyá
7+{2}/30= 30.0%
Xiǎoyún
5+{1}/30= 20.0%
|
nǐ hǎo
1/105=1.0%
kěyǐ
2/15=13.3%
|
qǐng jìn
6+{5}/30=36.7%
qǐng zuò
4+{1}/15=33.3%
qǐng wèn
4+{17}/45=46.7%
|
nǐ ne
1+{1}/15=
13.3%
wǒmen
10+{1}/60= 18.3%
nǎinai
3+{3}/15=4.0%
| |
23/120=
19.2%
|
33/120= 27.5%
|
3/120=
2.5%
|
37/90=
41.1%
|
19/90=
21.1%
|
115/540
=21.3%
| |
Tone 4 (à)
|
Lìbō
0+{2}/45=4.4%
|
bù máng
0/15=0.0%
wàipó
4+{3}/30=
23.3%
èr céng
1+{1}/15= 13.3%
Dàwéi
0+{2}/30= 6.7%
|
wàiyǔ
3+{3}/15= 40.0%
jìzhě
3+{1}/15=
2.7%
|
guì xìng
2+{8}/15=66.7%
sùshè
0/15=0.0%
zàijiàn
1+{10}/30=36.7%
|
bàba
1+{6}/15=
46.7%
jìnlai
2/15=13.3%
rènshi
7/30=23.3%
xièxie
1/30=3.3%
| |
2/45=
4.5%
|
11/90=
12.2%
|
10/30=
33.3%
|
21/60=
35.0%
|
17/90=
18.9%
|
61/315=19.3%
|
Table 7: Respective Percentages of Errors of the First Syllables in Disyllabic Tones
Table 6 and Table 7 show that when the first syllable is Tone 3, the percentage of errors was the highest (21.3%), followed by Tone 4 (5) (19.3%), Tone 1 (16.7%) and Tone 2 (13%). In the combination of Tone 3 and Tone 4, the percentage of Tone 3 being misprounced went up to 41.1%. As no significant difference of statistic results was found between the percentage of errors of Tone 3 and that of Tone 4 in the first syllable, it can be argued that Tone 4 does not present an easier task for learners than Tone 3.
The following two tables (Table 8 and Table 9) reveal that when the second syllable is Tone 4, the percentage of errors was the highest (42.9%), followed by Tone 1 (31%), Tone 2 (23.7%), Tone 3 (12.3%), and Tone 5 (8.7%):
Disyllabic Tones
|
Tone 1 (ā)
|
Tone 2 (á)
|
Tone 3 (ǎ)
|
Tone 4 (à)
|
Tone 5 (a)
|
Tone 1 (ā)
|
23.3%
|
8.9%
|
---
|
51.1%
|
10.5%
|
Tone 2 (á)
|
---
|
0%
|
5%
|
42.5%
|
6.7%
|
Tone 3 (ǎ)
|
27.5%
|
28.3%
|
12.5%
|
33.3%
|
7.8%
|
Tone 4 (à)
|
55.6%
|
28.9%
|
26.7%
|
51.7%
|
7.8%
|
31%
|
23.7%
|
12.4%
|
42.9%
|
8.3%
|
Table 8: Percentages of Errors of the Second Syllables in Disyllabic Tones
Disyllabic Tones
|
Tone 1 (ā)
|
Tone 2 (á)
|
Tone 3 (ǎ)
|
Tone 4 (à)
|
Tone 5 (a)
|
Tone 1 (ā)
|
kāfēi
17/60=28.3%
yīshēng
4/15=26.7%
cāntīng
0/15=0.0%
|
Zhōngguó
3/30=10.0%
Yīngguó
1/15=6.7%
|
---
|
gāoxìng
14+{2}/30=53.3%
zhīdào
6+{1}/15=46.7%
|
māma
2+{3}/15=33.3%
gēge
4/30=13.3%
tāmen
0/15=0.0%
xiānsheng
2/1513.3%
guānxi
0/30=0.0%
|
21/90=
23.3%
|
4 /45=
8.9%
|
---
|
23/45=
51.1%
|
11/105=
10.5%
| |
Tone 2 (á)
|
---
|
xuéxí
0/15=0.0%
|
nín hǎo
3/60=5.0%
|
Lín Nà
13+{2}/30=50.0%
xuéyuàn
22+{1}/30=76.7%
bú shì
4+{3}/45=15.6%
bú yòng
4+{2}/15=40.0%
|
péngyou
2+{1}/45=6.7%
xuésheng
2/30=6.7%
|
---
|
0/15=
0.0%
|
3/60=
5.0%
|
51/120= 42.5%
|
5/75=
6.7%
| |
Tone 3 (ǎ)
|
lǎoshī
22+{11}/120=
27.5%
|
Měiguó
0/15=0.0%
Yǔpíng
12+{7}/45=
42.2%
yǔyá
6+{2}/30= 26.7%
Xiǎoyún
6+{1}/30=
23.3%
|
nǐ hǎo
11/105=10.5%
kěyǐ
4/15=26.7%
|
qǐng jìn
0+{5}/30=16.7%
qǐng zuò
0+{1}/15=6.7%
qǐng wèn
7+{17}/45=53.3%
|
nǐ ne
0+{1}/15=6.7%
wǒmen
11+{1}/60=20.0%
nǎinai
1+{3}/15=26.7%
|
33/120=
27.5%
|
34/120=
28.3%
|
15/120=
12.5%
|
30/90=
33.3%
|
7/90=
7.8%
| |
Tone 4 (à)
|
Lìbō
23+{2}/45=
55.6%
|
bù máng
1/15=6.7%
wàipó
7+{3}/30=
33.3%
èr céng
4+{1}/15=
33.3%
Dàwéi
8+{2}/30=
33.3%
|
wàiyǔ
2+{3}/15=
33.3%
jìzhě
2+{1}/15=
20.0%
|
guì xìng
3+{8}/15=73.3%
sùshè
3/15=20.0%
zàijiàn
7+{10}/30=56.7%
|
bàba
0+{6}/15=40.0%
jìnlai
1/15=6.7%
rènshi
0/30=0.0%
xièxie
0/30=0.0%
|
25/45=
55.6%
|
26/90=
28.9%
|
8/30=
26.7%
|
31/60=
51.7%
|
7/90=
7.8%
| |
Error /
Occurrence
(in percent)
|
79/255=
31%
|
64/270=
23.7%
|
26/210=
12.4%
|
135/315=
42.9%
|
30/360=
8.3%
|
Table 9: Error Percentages of the Second Syllables in Disyllabic Tones
These findings suggest that the correct realisation of Tone 4 presents an even greater challenge when it resides in the second syllable than is the case with the first syllable. This may also help clarify cases like bù máng ('not busy') and sùshè ('student dormitory'), in which no tone error of the first syllable was found. This result also echoes the findings of Ding (2012), who worked on the perception and production of Mandarin disyllabic tones by German learners. According to Ding’s findings, the accuracy rate of the production of Tone 4 in the first syllable of Tone 4-Tone 4 combinations is 66 %, i.e. an error rate of 34%, while the accuracy rate of Tone 4 in the second syllable of the Tone 4-Tone 4 combination is fairly low, only reaching 28%, i.e. an error rate of 72%.
4.3 Research Factors
There are some factors that might have had an influential effect on the statistic results of the studies. These factors are the following ones:
- Two tone combinations, Tone 1-Tone 3 and Tone 2-Tone 1 of disyllabic tones are not available in the databank, for they are not covered in the first five lessons of the target textbook.
- Low numbers of entries in the tone combinations of Tone 2-Tone 2, Tone 2-Tone 3, Tone 3-Tone 1, and Tone 4-Tone 1 only have only one entry, respectively.
- Due to prosodic reasons, single monosyllabic words in structures such as Zhè shì ('This is...'), Nà shì ('That is…'), Wǒ jiào ('I am called…') and Wǒ xìng ('My surname is…') represent sentence patterns and are produced as whole meaningful units. Tones are not - and actually should not be - strictly marked at a single-word level, but rather at a disyllabic chunk-based level so as to keep the naturalness of language usage and prosody.
Although the above factors might have affected the results of the present study, the findings presented here do have their general pedagogic values and research implications, a point which we are turning to in the ensuing part.
5 Pedagogic Values and Research Implications
5.1 Teacher as Researcher and Learner Autonomy
Resulting from the findings of this study, the potential pedagogic values are primarily twofold:
- Teachers can work as researchers for their own students to document their learning progress and to provide them with feedback. Methodologically, this approach may lead to the enhancement of learners’ motivation in that it boosts learner autonomy (De Florio-Hansen 2016) if students are instructed how to access their own learning data.
- In the previous part, the author demonstrated how a language teacher could function as an independent, forefront researcher. By compiling a learner corpus of his or her students with their errors being tagged, and then employing a corpus analysis tool, such as AntConc, to conduct searches on these errors, a teacher can document the errors of his or her students and then provide individual feedback to students and collective feedback to the whole class.
Using the Wild Card function of AntConc, the author showed an alternative approach to the creation of word lists of different tone combinations in the form of tone combination charts. With this approach, a teacher can quickly build up vocabulary tables of word entries with different tone combinations from target resources such as course books or class handouts, which will serve as the best example templates for learners. The vocabulary tables provide students with a quick glance of the learned and / or new words and may have an i+1 scaffolding effect in boosting the facilitation of transferring correct pronunciation from the learned to the new words, i.e. a positive transfer from the old input to the new input. By drawing students’ attention to the correctly pronounced words and having students make transfers to words initially pronounced wrong or to new words, the teacher gives students the possibilities to auto-correct their own errors and, in the meanwhile, shows his or her support of learner autonomy.
Moreover, it is also important to note that while errors of words are presented for learning purposes, it would be advisable to have them displayed in contexts so that learners can envisage these errors in their naturally occurring situations. The screenshots (Figure 8 and Figure 9) below give an illustration of how this can be done:

Figure 8: Word Entries, Using the Concordance Function of AntConc
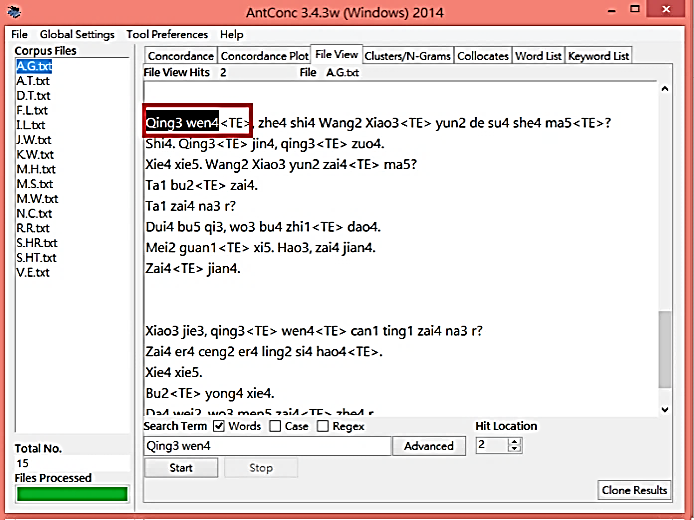
Figure 9: Word Entries in Their Natural Contexts, Using the File-View Function of AntConc
Take the disyllabic phrase qǐng wèn (qing3 wen4 'May I ask..?') as an example. By clicking on the very phrase in the concordance line, qǐng wèn will be presented under the function of ‘File View’ in the context where it is used. By utilising this function, the teacher can offer general feedback to the whole class and individualised feedback to students.
As mentioned above, with this corpus approach, teachers can work as researchers in action, so may students. It is imaginable that students, after being trained to use such a corpus tool, will be capable of compiling their own vocabulary tables and spot their own pronunciation errors in contexts, provided that the teacher gives them marked feedback, indicating the pronunciation errors in the form of tagged text files.
Based on the findings of the present study, Tone 4, which, due to its swift, falling pitch, is nicknamed as “the angry tone” by learners of Chinese, presents the most challenging one for students at a monosyllabic level. When it comes to disyllabic tones, Tone 4 in the second syllable presents a greater task for correct realisation than it is in the first syllable. Consequently, an important pedagogic issue would be the question of how teachers can develop strategies (Huang, Li & Zhang 2016) to help learners overcome this hurdle, for example by marking the tone contours of target words on music staves for learners of the visual type to envisage or by using gestures to present the tone contours for learners of the kinaesthetic type to imitate.
5.2 Research Limitations and Implications
The present study can inform teachers who take interest in having an insight into their students’ Chinese tone production. Nevertheless, by no means does it lay claim to comprehensiveness, and, above all, it has certain limitations.
A fundamental weak point of the study lies in the fact that its scope is partial and limited in that some entry examples of tone combinations are missing in the databank. Further research including word entries from additional lessons from the course book to expand the databank is therefore strongly suggested to conduct the study at a more comprehensive scale. In addition, the study was confined to the tone production of learners at the beginners’ level. It might be worth investigating learners’ performance at different learning stages.
Furthermore, the study did not fully employ the Chinese concept of the differentiation between single words 字zì, which contain only one syllable, i.e. a monosyllable, and multi-syllable words词cí. As stated in Chapter 2, the study operated on the sound level (monosyllabic and disyllabic) rather than on the word level. Monosyllabic units in disyllabic words and chunks were, for the research part, taken as entries at the monosyllabic level, while disyllabic chunks such as èr céng ('the second floor'), strictly speaking, are not regarded as词cí, but as a phrase.
A suggestion for further research may be an acoustic analysis of students’ oral production in a visual form, using open-source speech-analysing tools such as Praat and Speech Analyser, to continue exploring the issue of whether and how tonal contours in a visual form contribute to the improvement of German learners' tone performance, as Do et al. (2012) had tapped into, and, above all, to inspect how this approach can be employed in a normal classroom setting as well as how it is received by teachers.
6 Conclusion
The present study explored German students’ production of monosyllabic and disyllabic tones at the beginners' level by utilising the corpus analysis tool AntConc. In addition to demonstrating how texts from target resources can be processed and tables of monosyllabic and disyllabic tones with example entries can be compiled for use in a classroom setting, the study also shows how students’ commonly-made tonal errors can be identified so as to provide overall and individual feedback.
The statistic results of the study show that Tone 4, be it as a monosyllabic tone or as part of disyllabic tones, presented the greatest challenge for German learners of Chinese. Since the oral production of Tone 4 requires a wider f0 range of a drop from 5 to 1 on the musical scale, it is not surprising that Tone 4 is nicknamed ‘the angry tone’ by German learners. Tone 3, though not as problematic as it had been presumed to be as a monosyllabic tone, appeared to be a cumbersome one for learners when residing in the first syllable of disyllabic tones - in the combination of Tone 3 and Tone 4 in particular. These findings may provide an insight for Chinese teachers who start working with German students. Finally, the study suggested that further research with an expanded databank could be pursued to inspect if the same results will be confirmed at different learning stages.
References
Almelaifi, Ruba (2013). The Role of “Focus of Attention” on the Learning of Non-native Speech Sounds: English Speakers Learning of Mandarin Chinese Tones. Doctoral Dissertation. Pittsburgh, PA: University of Pittsburgh.
Anthony, Laurence (2014). AntConc (Version 3.4.3) [Computer Software]. Tokyo, Japan: Waseda University.
Brengelmann, Tingting, Francesco Cangemi & Martine Grice (2015). Tonal Coarticulation in German Learners of Standard Chinese. Poster Presentation. Phonetics and Phonology in Europe 2015 (PaPE), Cambridge, UK. (https://www.internationalphoneticassociation.org/icphsproceedings/ICPhS2015/Papers/ICPHS0316.pdf; 23-05-2017).
Cao, Wen (2016). When and How Shall Tones Be Taught in Chinese Learning? In: ISAPh International Symposium on Applied Phonetics (2016), 30-33.
Chao, Yuan-Ren (1933). Tone and Intonation in Chinese. In: Bulletin of the Institute of History and Philology, Academia Sinica 4 (1933) 2, 121-134.
Chen, Ching-Yu et al. (1993). Some Distributional Properties of Mandarin Chinese – A Study Based on the Academia Sinica Corpus. In: Proceedings of Pacific Asia Conference on Formal and Computational Linguistics I (1993), 81-95.
De Florio-Hansen, Inez (2016). Vom effektiven Lehren zum erfolgreichen Fremdsprachenlernen – Grundlagen eines wissenschaftsorientierten Unterrichts. In: Journal of Linguistics and Language Teaching 7 (2016) 2, 219-255.
Ding, Hongwei (2012). Perception and Production of Mandarin Disyllabic Tones by German Learners. In: Speech Prosody – Sixth International Conference (2012), 378-381.
Ding, Hongwei, Rüdiger Hoffmann & Oliver Jokisch (2011). An Investigation of Tone Perception and Production in German Learners of Mandarin. In: Archives of Acoustics 36 (2011) 3, 509-518.
Do, Hue San et al. (2012). Evaluation of Benefits from a Computer-aided Pronunciation Training System for German Learners of Mandarin Chinese. In: Speech Prosody-Sixth International Conference Shanghai (2012), 362-365.
Guo, Lijuan & Liang Tao (2008). Tone Production in Mandarin Chinese by American Students: A Case study. In: Proceedings of the 20th North American Conference on Chinese Linguistics 1, 123.
Hao, Yen-Chen (2012). Second Language Acquisition of Mandarin Chinese Tones by Tonal and Non-tonal Language Speakers. In: Journal of Phonetics 40 (2012) 2, 269-279.
He, Yunjuan, Qian Wang & Ratree Wayland (2016). Effects of Different Teaching Methods on the Production of Mandarin Tone 3 by English Speaking Learners. In: The Journal of the Chinese Language Teachers Association, USA, 51(2016) 3, 252-265.
Huang, Lifang, Li Li & Yang Zhang (2016). Effects of Tone Training on Mandarin Tones Learning of Chinese-as-a-Second-Language Learners. In: Advances in Psychology 6 (2016) 7, 764-772.
Hunold, Cordula (2004). Probleme der chinesischen Phonetik für deutsche Chinesischlernende. In: Chun (Chinesischunterricht) 19 (2004), 33-48.
Hussein, Hussein et al. (2011). Mandarin Tone Perception and Production by German Learners. In: Speech and Language Technology in Education (2011), 149-152.
(http://project.cgm.unive.it/events/SLaTE2011/papers/Hussein--2011SLaTE_HusseinDoMix dorff_ FinalVersion.pdf; 23-05-2017)
Klein, Denise et al. (2001). A Cross-linguistic PET Study of Tone Perception in Mandarin Chinese and English Speakers. In: Neuroimage 13 (2001) 4, 646-653.
Lee, Chao-Yang, Liang Tao & Zinny S. Bond (2010). Identification of Acoustically Modified Mandarin Tones by Non-native Listeners. In: Language and Speech 53 (2010) 2, 217-243.
Lee, David (2015). Bookmarks for Corpus-based Linguists. (http://www.uow.edu.au/~dlee/CBL Links.htm; 25-10-2015).
Li, Charles N. & Sandra A. Thompson (1977). The Acquisition of Tone in Mandarin-speaking Children. In: Journal of Child Language 4 (1977) 2, 185-199.
Li, Man & Robert DeKeyser (2017). Perception, Practice, Production Practice, and Musical Ability in L2 Mandarin Tone-Word Learning. In: Studies in Second Language Acquisition 39 (2017) 4, 593-620.
Li, Ping et al. (Eds.) (2006). The Handbook of East Asian Psycholinguistics: Volume 1, Chinese. Cambridge: Cambridge University Press.
Lin, William CJ. (1985). Teaching Mandarin Tones to Adult English Speakers: Analysis of Difficulties with Suggested Remedies. In: RELC Journal 16 (1985) 2, 31-47.
Liu, Xun (2005). New Practical Chinese Reader. Vol 1 (English and Chinese Edition). Bejing: Beijing Language and Culture University Press; 2nd Edition.
吕叔湘 (Lü, Shuxiang) (1963). 现代汉语单双音节问题初探. 中国语文 (1), 10-22.
Miracle, W. Charles (1989). Tone Production of American Students of Chinese: A Preliminary Acoustic Study. In: Journal of Chinese Language Teachers Association 24 (1989) 3, 49-65.
Orton, John (2013). Developing Chinese oral skills: A Research Base for Practice. Research in Chinese as a second language, 9-32.
Parise, Peter (2015). A Brief Guide to Corpus Analysis Tools. (https://tesolpeter.wordpress.com/a-brief-guide-to-corpus-analysis-tools/; 23-05-2017).
Peng, Gang et al. (2010). The Influence of Language Experience on Categorical Perception of Pitch Contours. In: Journal of Phonetics 38 (2010) 4, 616-624.
San, Duanmu (1999). Stress and the Development of Disyllabic Words in Chinese. In: Diachronica 16 (1999) 1, 1-35.
Shen, Xiaonan Susan (1989). Toward a Register Approach in Teaching Mandarin Tones. In: Journal of the Chinese Language Teachers Association 24 (1989) 3, 27-47.
Shi, Yuzhi (2002). The Establishment of Modern Chinese Grammar: The Formation of the Resultative Construction and its Effects Vol. 59. Amsterdam: John Benjamins.
Shibagaki, Ryosuke (2014). Analysing Secondary Predication in East Asian Languages. Cambridge: Cambridge Scholars.
Tong, Rong, Nancy F. Chen, Bin Ma & Haizhou Li (2015). Goodness of Tone (GOT) for Non-Native Mandarin Tone Recognition. In: Sixteenth Annual Conference of the International Speech Communication Association (2015), 801-805.
Tsai, Rachel (2011). Teaching and Learning the Tones of Mandarin Chinese. In: Scottish Languages Review 24 (2011), 43-50.
Tillmann, Hans G. & Hartmut R. Pfitzinger (2004). Applying the Munich Parametric High Definition (PHD) Speech Synthesis System to the Problem of Teaching Chinese Tones to L1 Speakers of German. In: International Symposium on Tonal Aspects of Languages: With Emphasis on Tone Languages.
Wang, Yue, Allard Jongman & Joan A. Sereno (2003). Acoustic and Perceptual Evaluation of Mandarin Tone Productions before and after Perceptual Training. In: The Journal of the Acoustical Society of America 113 (2003) 2, 1033-1043.
Wang, Yue et al. (1999). Training American Listeners to Perceive Mandarin Tones. In: The Journal of the Acoustical Society of America 106 (1999) 6, 3649-3658.
White, Carolyn M. (1981). Tonal Perception Errors and Interference from English Intonation. In: Journal of the Chinese Language Teachers Association 16 (1981) 2, 27-56.
Yang, Chunsheng & Marjorie KM. Chan (2010). The Perception of Mandarin Chinese Tones and Intonation by American Learners. In: Journal of Chinese Language Teachers Association 45 (2010) 1, 7-36
Zhang, Felicia Zhen (2006). The Teaching of Mandarin Prosody: A Somatically-enhanced Approach for Second Language Learners. Doctoral Dissertation. Canberra: University of Canberra. Division of Communication and Education.
Author:
Yi-Ling Lillian Tinnefeld-Yeh
Adjunct Chinese Instructor
Saarland University of Applied Sciences
14, Waldhausweg
66123 Saarbrücken
Germany
Email: Y.Tinnefeld-Yeh@htw-saar.de
1 David Lee’s website where the list of concordancers was indicated was taken over by Martin Weisser on 20-01-2016. http://martinweisser.org/corpora_site/corpuslinksHOME.html. The list is available at http://martinweisser.org/corpora_site/concordancers.html; 23-10-2017.
2 A Chinese written sign - or more precisely, a Chinese character 字zì - is composed of one syllable. A Chinese word 词cí can be a single character 字zì or a combination of more than two characters. In the latter case, a Chinese word is polysyllabic and possesses more than two syllables.
3 The syllables marked in grey represent the respective cotexts (i.e. 词cí) of those monosyllabic words (i.e. 字zì) that were pronounced wrong by students.
4 Yet, bearing this issue in mind, the author examined the entries of the Tone 3-Tone 3 combination and found a low error rate of 2.5%.
5 In the case of the Tone 4-Tone 4 combination, the first Tone 4 is truncated. That is, the tone does not drop from a high level to a low level, but from a high level to a middle level. This factor had already been taken into consideration during the error identification procedure.
1 David Lee’s website where the list of concordancers was indicated was taken over by Martin Weisser on 20-01-2016. http://martinweisser.org/corpora_site/corpuslinksHOME.html. The list is available at http://martinweisser.org/corpora_site/concordancers.html; 23-10-2017.
2 A Chinese written sign - or more precisely, a Chinese character 字zì - is composed of one syllable. A Chinese word 词cí can be a single character 字zì or a combination of more than two characters. In the latter case, a Chinese word is polysyllabic and possesses more than two syllables.
3 The syllables marked in grey represent the respective cotexts (i.e. 词cí) of those monosyllabic words (i.e. 字zì) that were pronounced wrong by students.
4 Yet, bearing this issue in mind, the author examined the entries of the Tone 3-Tone 3 combination and found a low error rate of 2.5%.
5 In the case of the Tone 4-Tone 4 combination, the first Tone 4 is truncated. That is, the tone does not drop from a high level to a low level, but from a high level to a middle level. This factor had already been taken into consideration during the error identification procedure.